k-nejbližší sousedé: kdo je vám blízký?
pokud jdete na vysokou školu, pravděpodobně jste se zúčastnili alespoň několika studentských organizací. Začínám svůj 1. semestr jako postgraduální student na Rochester Tech, a existuje více než 350 organizace zde. Jsou řazeny do různých kategorií na základě zájmů studenta. Co definuje tyto kategorie a kdo říká, který org jde do jaké kategorie? Jsem si jistý, že kdybyste se zeptali lidí, kteří řídí tyto organizace, neřekli by, že jejich org je jako org někoho jiného, ale nějakým způsobem víte, že jsou podobné., Bratrství a spolky mají stejný zájem o řecký život. Intramurální fotbal a klubový tenis mají stejný zájem o sport. Skupina Latino a Asijská americká skupina mají stejný zájem o kulturní rozmanitost. Možná, že pokud změříte události a schůzky vedené těmito Orgy, můžete automaticky zjistit, do jaké kategorie organizace patří. Použiji studentské organizace k vysvětlení některých konceptů k-nejbližších sousedů, pravděpodobně nejjednoduššího algoritmu strojového učení. Sestavení modelu spočívá pouze v uložení tréninkového datasetu., Aby se předpověď pro nová data, algoritmus najde nejbližší datové body v tréninku dataset — jeho „nejbližších sousedů.“
jak to funguje
ve své nejjednodušší verzi algoritmus k-NN zvažuje pouze jednoho nejbližšího souseda,což je nejbližší tréninkový datový bod k bodu, pro který chceme předpovědět. Predikce je pak prostě známý výstup pro tento tréninkový bod., Obrázek níže ilustruje tento případ klasifikace na kovárně dataset:

Zde přidali jsme tři nové datové body zobrazeny jako hvězdičky. Pro každou z nich jsme označili nejbližší bod v tréninkové sadě. Predikce algoritmu jednoho nejbližšího souseda je označení tohoto bodu (zobrazené barvou kříže).
místo toho, abychom uvažovali pouze o nejbližším sousedovi, můžeme také zvážit libovolné číslo, k, sousedů., Odtud pochází název algoritmu k-nejbližší sousedé. Při zvažování více než jednoho souseda používáme hlasování k přiřazení štítku. To znamená, že pro každý zkušební bod počítáme, kolik sousedů patří do třídy 0 a kolik sousedů patří do třídy 1. Pak přiřadíme třídu, která je častější: jinými slovy, většinová třída mezi nejbližšími sousedy k., Následující příklad používá pět nejbližších sousedů:
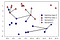
Opět, predikce je zobrazen jako barva kříže. Můžete vidět, že předpověď pro nový datový bod vlevo nahoře není stejná jako predikce, když jsme použili pouze jednoho souseda.
zatímco tento obrázek je pro binární klasifikační problém, tato metoda může být použita pro datové sady s libovolným počtem tříd., Pro více tříd počítáme, kolik sousedů patří do každé třídy A opět předpovídáme nejběžnější třídu.,uvolňování pořadí
Python kód pro funkci je zde:
Pojďme kopat trochu hlouběji do kódu:
- funkce knnclassify trvá 4 vstupy: vstupní vektor klasifikovat říká, plné matice trénovacích příkladů názvem datové sady, vektor štítky tzv. štítky, a k — počet nejbližších sousedů k použití v hlasování., Vektor štítků by měl mít v sobě tolik prvků, kolik je řádků v matici datových sad.
- pomocí euklidovské vzdálenosti vypočítáme vzdálenosti mezi A a aktuálním bodem.
- pak třídíme vzdálenosti v rostoucím pořadí.
- Další, nejnižší k vzdálenosti se používají k hlasování o třídy a.
- Po tom, bereme classCount slovník a rozložit je do seznamu, n-tice a pak třídit n-tic 2. bod v n-tice. Tento druh se provádí v opačném směru, takže máme největší až nejmenší.,
- nakonec vrátíme štítek položky, která se vyskytuje nejčastěji.
Provádění Prostřednictvím Scikit-Learn
Nyní se pojďme podívat na to, jak můžeme realizovat kNN algoritmu pomocí scikit-learn:
Pojďme se podívat do kódu:
- za Prvé, musíme vytvořit iris dataset.
- poté jsme naše data rozdělili na tréninkovou a testovací sadu pro vyhodnocení generalizačního výkonu.
- dále zadáme počet sousedů (k) až 5.
- dále použijeme klasifikátor pomocí tréninkové sady.,
- Chcete-li provést předpovědi o testovacích datech, nazýváme metodu predict. Pro každý datový bod v testovací sadě metoda vypočítá své nejbližší sousedy v tréninkové sadě a najde mezi nimi nejběžnější třídu.
- nakonec vyhodnocujeme, jak dobře se náš model zobecňuje, voláním metody skóre pomocí testovacích dat a testovacích štítků.
spuštění modelu by se nám dává test nastavit přesnost 97%, což znamená, že model předpověděl třídy správně 97% vzorků v testovací dataset.,

Silné a Slabé stránky
V zásadě existují dva důležité parametry KNeighbors klasifikátor: počet sousedů a jak budete měřit vzdálenost mezi body dat.
- v praxi použití malého počtu sousedů, jako jsou tři nebo pět, často funguje dobře, ale tento parametr byste měli určitě upravit.
- výběr správného měření vzdálenosti je poněkud komplikovaný., Ve výchozím nastavení se používá euklidovská vzdálenost, která funguje dobře v mnoha nastaveních.
jednou ze silných stránek k-NN je to, že model je velmi snadno pochopitelný a často poskytuje přiměřený výkon bez mnoha úprav. Použití tohoto algoritmu je dobrá základní metoda, kterou můžete vyzkoušet před zvážením pokročilejších technik. Stavební nejbližší sousedy model je obvykle velmi rychlé, ale když váš tréninkový set je velmi velký (buď v množství funkcí nebo v počtu vzorků) predikce může být pomalé. Při použití algoritmu k-NN je důležité předzpracovat data., Tento přístup často není dobře hrát na soubory dat s mnoha funkcemi (stovky a více), a to zejména špatně se soubory dat, kde většina funkcí jsou 0 nejvíce času (tzv. řídké soubory dat).
na závěr
algoritmus k-nejbližší sousedé je jednoduchý a účinný způsob klasifikace dat. Je to příklad učení založené na instanci, kde musíte mít po ruce instance dat, abyste mohli provádět algoritmus strojového učení. Algoritmus musí přenášet celou datovou sadu; u velkých datových sad to znamená velké množství úložiště., Kromě toho musíte vypočítat měření vzdálenosti pro každý kus dat v databázi, což může být těžkopádné. Další nevýhodou je, že kNN nedává žádnou představu o základní struktuře dat; nemáte ponětí, co je to „průměrná“ nebo „vzorek“ instance od každé třídy vypadá.
takže zatímco nejbližší algoritmus k-sousedé je snadno pochopitelný, v praxi se často nepoužívá, protože predikce je pomalá a její neschopnost zvládnout mnoho funkcí.,
Referenční Zdroje:
- Učení Stroj V Akci Peter Harrington (2012)
- Úvod do Strojového Učení s Python Sarah Guido a Andreas Muller (2016)















