Koncové Mezery v SQL Server
Sledujte tento týden je video na YouTube,
dávno postavil jsem aplikaci, která zachytil vstup uživatele. Jednou z funkcí aplikace bylo porovnat vstup uživatele s databází hodnot.
aplikace provedla toto srovnání textu jako součást procedury uložené na serveru SQL, což mi v případě potřeby umožnilo snadno aktualizovat obchodní logiku.
jednoho dne jsem obdržel e-mail od uživatele, který říká, že hodnota, kterou zadali, odpovídá databázové hodnotě, o které věděli, že by se neměla shodovat., To je den, kdy jsem objevil SQL Server counter intuitivní srovnání rovnosti při jednání s koncovými znaky prostoru.
Čalouněný bílý prostor
Jste pravděpodobně vědomi toho, že CHAR datový typ podložky hodnota s mezerami až do definované délky je dosaženo:
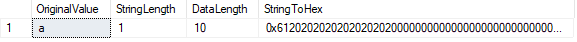
LEN() funkce zobrazuje počet znaků v našem řetězci, zatímco DATADÉLKA() funkce nám ukazuje počet bajtů, které používá řetězec.
v tomto případě se DATALENGTH rovná 10., Tento výsledek je způsoben polstrovanými mezerami vyskytujícími se po znaku „a“, aby se vyplnila definovaná délka znaků 10. Můžeme to potvrdit převedením hodnoty na hexadecimální. Vidíme hodnotu 61 („a“ v hex) následovanou devíti hodnotami “ 20 “ (mezery).
Pokud změníme naše proměnná je datový typ VARCHAR, uvidíme hodnota je již čalouněný s mezerami:

Vzhledem k tomu, že jeden z těchto typů dat podložky hodnoty s prostorem znaky, zatímco ostatní neví, co se stane, když budeme porovnávat dva?,
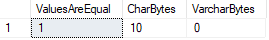
V tomto případě SQL Server domnívá se obě hodnoty rovnají, i když můžeme potvrdit, že DATALENGTHs jsou různé.
toto chování se však nevyskytuje pouze u smíšených srovnání datového typu. Porovnáme-li dvě hodnoty stejného datového typu, s jednou hodnotou obsahující několik znaků prostoru, něco zažijeme…nečekané:

I když naše dvě proměnné mají různé hodnoty (prázdné ve srovnání s čtyři znaky), SQL Server domnívá se tyto hodnoty rovnají.,
Pokud přidáme znak s některými koncové mezery uvidíme, stejné chování.

Obě hodnoty jsou zřetelně odlišné, ale SQL Server považuje za navzájem rovné. Přepínání naše znaménko rovná se, podobně JAKO operátor změny věci mírně:

I když bych si myslel, že JAKO bez žádné zástupné znaky se chovají stejně jako rovnítko, SQL Server nemusí provádět tato srovnání stejným způsobem.,
Pokud se přepneme zpět do našeho rovnítko srovnání a prefix našeho charakteru hodnota s mezerami budeme také všimnout, jiný výsledek:

SQL Server považuje za dvě hodnoty stejné, bez ohledu na mezery vyskytující se na konci provázku. Mezery před řetězcem však již nejsou považovány za shodu.
co se děje?
ANSI
zatímco counter intuitivní, funkčnost SQL Serveru je oprávněná., SQL Server se řídí specifikací ANSI pro porovnání řetězců a přidává bílý prostor řetězcům tak, aby byly stejné délky před jejich porovnáním. To vysvětluje jevy, které vidíme.
to však nedělá s podobným operátorem, což vysvětluje rozdíl v chování.
srovnání, když další mezery záleží
řekněme, že chceme provést srovnání, kde záleží na rozdílu v koncových prostorech.
jednou z možností je použít podobného operátora, když jsme viděli několik příkladů zpět., Nejedná se však o typické použití podobného operátora, takže nezapomeňte komentovat a vysvětlit, co se Váš dotaz pokouší udělat jeho použitím. Poslední věc, kterou chcete, je nějaký budoucí správce vašeho kódu, aby jej přepnul zpět na stejné znaménko, protože nevidí žádné znaky divoké karty.
Další možnost, kterou jsem viděl, je provést DATADÉLKA srovnání kromě hodnoty srovnání:

Toto řešení není správné pro každý scénář však., Pro začátečníky, nemáte žádný způsob, jak zjistit, zda SQL Server provede nejprve srovnání hodnoty nebo predikát DATALENGTH. To by mohlo zničit zmatek při používání indexu a způsobit špatný výkon.
závažnější problém může nastat, pokud porovnáváte pole s různými typy dat., Například, při porovnání VARCHAR k NVARCHAR typ dat, je to docela snadné vytvořit scénář, kde se vaše srovnání dotazu pomocí DATADÉLKA bude vyvolat falešně pozitivní:

Zde NVARCHAR obchody, 2 bajty pro každý znak, což DATALENGTHs o jeden znak NVARCHAR rovná znak + prostor VARCHAR hodnoty.
nejlepší věcí v těchto scénářích je porozumět vašim datům a vybrat řešení, které bude fungovat pro vaši konkrétní situaci.,
a možná ořízněte data před vložením (pokud to má smysl)!















