k-Nächste Nachbarn: Wer sind in Ihrer Nähe?
Wenn Sie aufs college gehen, werden Sie wahrscheinlich an mindestens ein paar studentische Organisationen. Ich beginne mein 1. Semester als Doktorand an der Rochester Tech, und es gibt mehr als 350 Organisationen hier. Sie werden nach den Interessen des Schülers in verschiedene Kategorien eingeteilt. Was definiert diese Kategorien, und wer sagt, welche org geht in welche Kategorie? Ich bin sicher, wenn Sie die Leute fragen, die diese Organisationen leiten, würden sie nicht sagen, dass ihre Organisation genau wie die einer anderen Organisation ist, aber in gewisser Weise wissen Sie, dass sie ähnlich sind., Bruderschaften und sororities haben das gleiche Interesse am griechischen Leben. Intramuraler Fußball und Clubtennis haben das gleiche Interesse am Sport. Die Latino-Gruppe und die asiatisch-amerikanische Gruppe haben das gleiche Interesse an kultureller Vielfalt. Wenn Sie die Ereignisse und Besprechungen dieser Organisationen messen, können Sie möglicherweise automatisch herausfinden, zu welcher Kategorie eine Organisation gehört. Ich werde Studentenorganisationen verwenden, um einige der Konzepte von k-Nearest Neighbors zu erklären, wohl der einfachste Algorithmus für maschinelles Lernen. Das Erstellen des Modells besteht nur aus dem Speichern des Trainingsdatensatzes., Um eine Vorhersage für einen neuen Datenpunkt zu treffen, findet der Algorithmus die nächstgelegenen Datenpunkte im Trainingsdatensatz — seine “ nächsten Nachbarn.“
Wie es funktioniert
In seiner einfachsten Version berücksichtigt der k-NN-Algorithmus nur genau einen nächsten Nachbarn, der dem Punkt am nächsten ist, für den wir eine Vorhersage treffen möchten. Die Vorhersage ist dann einfach die bekannte Ausgabe für diesen Trainingspunkt., Abbildung unten zeigt dies für den Fall der Klassifizierung im Forge-Datensatz:

Hier haben wir drei neue Datenpunkte hinzugefügt, als Sterne dargestellt. Für jeden von ihnen haben wir den nächsten Punkt im Trainingssatz markiert. Die Vorhersage des One-Nearest-Neighbor-Algorithmus ist die Bezeichnung dieses Punktes (dargestellt durch die Farbe des Kreuzes).
Anstatt nur den nächsten Nachbarn zu betrachten, können wir auch eine beliebige Zahl, k, von Nachbarn betrachten., Hier kommt der Name des k-nearest neighbors Algorithmus her. Wenn wir mehr als einen Nachbarn betrachten, verwenden wir Voting, um ein Label zuzuweisen. Dies bedeutet, dass wir für jeden Testpunkt zählen, wie viele Nachbarn zur Klasse 0 gehören und wie viele Nachbarn zur Klasse 1 gehören. Wir weisen dann die Klasse zu, die häufiger ist: mit anderen Worten, die Mehrheitsklasse unter den k-nächsten Nachbarn., Das folgende Beispiel verwendet die fünf nächsten Nachbarn:
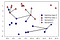
Erneut, die Vorhersage wird gezeigt, wie die Farbe des Kreuzes. Sie können sehen, dass die Vorhersage für den neuen Datenpunkt oben links nicht mit der Vorhersage übereinstimmt, wenn wir nur einen Nachbarn verwendet haben.
Während diese Abbildung für ein binäres Klassifizierungsproblem ist, kann diese Methode auf Datensätze mit einer beliebigen Anzahl von Klassen angewendet werden., Für weitere Klassen zählen wir, wie viele Nachbarn zu jeder Klasse gehören, und prognostizieren erneut die häufigste Klasse.,Lockerungsreihenfolge
Der Python — Code für die Funktion ist hier:
Lassen Sie uns ein wenig tiefer in den Code eintauchen:
- Die Funktion knnclassify benötigt 4 Eingaben: Der zu klassifizierende Eingabevektor heißt A, eine vollständige Matrix von Trainingsbeispielen namens dataSet, ein Vektor von Labels namens labels und k-die Anzahl der nächsten Nachbarn, die in der Abstimmung verwendet werden sollen., Der Beschriftungsvektor sollte so viele Elemente enthalten, wie Zeilen in der Datensatzmatrix vorhanden sind.
- Wir berechnen die Abstände zwischen A und dem aktuellen Punkt anhand der euklidischen Entfernung.
- Dann sortieren wir die Abstände in aufsteigender Reihenfolge.
- Als nächstes werden die niedrigsten k-Abstände verwendet, um über die Klasse von A.
- Danach nehmen wir das classCount-Wörterbuch und zerlegen es in eine Liste von Tupeln und sortieren dann die Tupel nach dem 2.Element im Tupel. Die Sortierung erfolgt umgekehrt, sodass wir die größte bis kleinste haben.,
- Zuletzt geben wir das Etikett des Artikels am häufigsten zurück.
Implementierung über Scikit-Learn
Schauen wir uns nun an, wie wir den kNN-Algorithmus mit scikit-learn implementieren können:
Schauen wir uns den Code an:
- Zuerst generieren wir den Iris-Datensatz.
- Dann teilen wir unsere Daten in einen Trainings-und Testsatz auf, um die Verallgemeinerungsleistung zu bewerten.
- Als nächstes geben wir die Anzahl der Nachbarn (k) bis 5 an.
- Als nächstes passen wir den Klassifikator mit dem Trainingssatz an.,
- Um Vorhersagen für die Testdaten zu treffen, rufen wir die Predict-Methode auf. Für jeden Datenpunkt im Testsatz berechnet die Methode ihre nächsten Nachbarn im Trainingssatz und findet die häufigste Klasse unter ihnen.
- Abschließend bewerten wir, wie gut sich unser Modell verallgemeinert, indem wir die Score-Methode mit Testdaten und Testetiketten aufrufen.
Wenn wir das Modell ausführen, erhalten wir eine Testsatzgenauigkeit von 97%, was bedeutet, dass das Modell die Klasse für 97% der Stichproben im Testdatensatz korrekt vorhergesagt hat.,

Stärken und Schwächen
Im Prinzip gibt es zwei wichtige parameter zum KNeighbors-Klassifikator: Die Anzahl der Nachbarn und wie Sie den Abstand zwischen Datenpunkten messen.
- In der Praxis funktioniert die Verwendung einer kleinen Anzahl von Nachbarn wie drei oder fünf oft gut, aber Sie sollten diesen Parameter auf jeden Fall anpassen.
- Die Wahl des richtigen Abstandsmaßes ist etwas schwierig., Standardmäßig wird der euklidische Abstand verwendet, was in vielen Einstellungen gut funktioniert.
Eine der Stärken von k-NN ist, dass das Modell sehr leicht zu verstehen ist und oft eine angemessene Leistung ohne viele Anpassungen bietet. Die Verwendung dieses Algorithmus ist eine gute Basismethode, die Sie ausprobieren sollten, bevor Sie fortgeschrittenere Techniken in Betracht ziehen. Das Erstellen des Modells der nächsten Nachbarn ist normalerweise sehr schnell, aber wenn Ihr Trainingssatz sehr groß ist (entweder in der Anzahl der Features oder in der Anzahl der Samples), kann die Vorhersage langsam sein. Wenn Sie den k-NN-Algorithmus verwenden, ist es wichtig, Ihre Daten vorab zu verarbeiten., Dieser Ansatz funktioniert bei Datensätzen mit vielen Funktionen (Hunderte oder mehr) häufig nicht gut und bei Datensätzen, bei denen die meisten Funktionen meistens 0 sind (sogenannte spärliche Datensätze), besonders schlecht.
Zusammenfassend
Der k-Nearest Neighbors-Algorithmus ist eine einfache und effektive Möglichkeit, Daten zu klassifizieren. Es ist ein Beispiel für instanzbasiertes Lernen, bei dem Sie Instanzen von Daten in der Nähe haben müssen, um den Algorithmus für maschinelles Lernen auszuführen. Der Algorithmus muss den gesamten Datensatz mit sich führen; Bei großen Datensätzen bedeutet dies eine große Menge an Speicher., Darüber hinaus müssen Sie die Entfernungsmessung für jedes Datenelement in der Datenbank berechnen, was umständlich sein kann. Ein zusätzlicher Nachteil ist, dass kNN Ihnen keine Vorstellung von der zugrunde liegenden Struktur der Daten gibt; Sie haben keine Ahnung, wie eine „durchschnittliche“ oder „exemplarische“ Instanz aus jeder Klasse aussieht.
Während der nächste k-Neighbors-Algorithmus leicht zu verstehen ist, wird er in der Praxis nicht häufig verwendet, da die Vorhersage langsam ist und viele Funktionen nicht verarbeitet werden können.,
Referenzquellen:
- Maschinelles Lernen in Aktion von Peter Harrington (2012)
- Einführung in maschinelles Lernen mit Python von Sarah Guido und Andreas Müller (2016)















