Trailing Spaces in SQL Server
Sehen Sie sich das Video dieser Woche auf YouTube
an Vor langer Zeit habe ich eine Anwendung erstellt, die Benutzereingaben erfasst hat. Eine Funktion der Anwendung bestand darin, die Eingaben des Benutzers mit einer Wertedatenbank zu vergleichen.
Die App führte diesen Textvergleich als Teil einer gespeicherten SQL Server-Prozedur durch, sodass ich die Geschäftslogik bei Bedarf in Zukunft problemlos aktualisieren konnte.
Eines Tages erhielt ich eine E-Mail von einem Benutzer, in der stand, dass der eingegebene Wert mit einem Datenbankwert übereinstimmte, von dem er wusste, dass er nicht übereinstimmen sollte., An diesem Tag habe ich den kontraproduktiven Gleichheitsvergleich von SQL Server beim Umgang mit nachgestellten Leerzeichen entdeckt.
Aufgefüllter Leerraum
Sie wissen wahrscheinlich, dass der Datentyp CHAR den Wert mit Leerzeichen auffüllt, bis die definierte Länge erreicht ist:
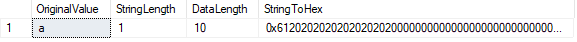
Die Funktion LEN() zeigt die Anzahl der Zeichen in unserer Zeichenfolge an, während die Funktion DATALENGTH() die Anzahl der von dieser Zeichenfolge verwendeten Bytes anzeigt.
In diesem Fall ist DATALENGTH gleich 10., Dieses Ergebnis ist auf die aufgefüllten Leerzeichen zurückzuführen, die nach dem Zeichen „a“ auftreten, um die definierte Zeichenlänge von 10 zu füllen. Wir können dies bestätigen, indem wir den Wert in hexadezimal konvertieren. Wir sehen den Wert 61 („a“ in hex), gefolgt von neun „20“ – Werte (Bereiche).
Wenn wir den Datentyp unserer Variablen in VARCHAR ändern, wird der Wert nicht mehr mit Leerzeichen aufgefüllt:

Da einer dieser Datentypen Werte mit Leerzeichen auffüllt, während der andere nicht, was passiert, wenn wir die beiden vergleichen?,
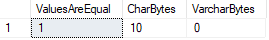
In diesem Fall betrachtet SQL Server beide Werte als gleich, obwohl wir bestätigen können, dass die Datenlängen unterschiedlich sind.
Dieses Verhalten tritt jedoch nicht nur bei gemischten Datentypvergleichen auf. Wenn wir zwei Werte desselben Datentyps mit einem Wert vergleichen, der mehrere Leerzeichen enthält, erleben wir etwas…unerwartet:

Obwohl unsere beiden Variablen unterschiedliche Werte haben (ein Leerzeichen im Vergleich zu vier Leerzeichen), betrachtet SQL Server diese Werte als gleich.,
Wenn wir ein Zeichen mit einem nachgestellten Leerzeichen hinzufügen, sehen wir dasselbe Verhalten:

Beide Werte unterscheiden sich deutlich, aber SQL Server betrachtet sie als gleich. Das Umschalten unseres Gleichheitszeichens auf einen LIKE-Operator ändert die Dinge geringfügig:

Obwohl ich denken würde, dass sich ein LIKE ohne Platzhalterzeichen genauso verhält wie ein Gleichheitszeichen führt SQL Server diese Vergleiche nicht auf die gleiche Weise aus.,
Wenn wir zu unserem Gleichheitszeichenvergleich zurückkehren und unserem Zeichenwert Leerzeichen voranstellen, werden wir auch ein anderes Ergebnis feststellen:

SQL Server betrachtet zwei Werte gleich, unabhängig von Leerzeichen am Ende einer Zeichenfolge. Leerzeichen vor einer Zeichenfolge werden jedoch nicht mehr als Übereinstimmung betrachtet.
Was ist Los?
ANSI
Die Funktionalität von SQL Server ist zwar kontraintuitiv, aber gerechtfertigt., SQL Server folgt der ANSI-Spezifikation zum Vergleichen von Zeichenfolgen und fügt Zeichenfolgen Leerzeichen hinzu, sodass sie vor dem Vergleich dieselbe Länge haben. Dies erklärt die Phänomene, die wir sehen.
Dies geschieht jedoch nicht mit dem ÄHNLICHEN Operator, was den Unterschied im Verhalten erklärt.
Vergleiche, wenn zusätzliche Leerzeichen wichtig sind
Angenommen, wir möchten einen Vergleich durchführen, bei dem der Unterschied in nachgestellten Leerzeichen wichtig ist.
Eine Option besteht darin, den LIKE-Operator zu verwenden, wie wir einige Beispiele gesehen haben., Dies ist jedoch nicht die typische Verwendung des LIKE-Operators, also kommentieren und erklären Sie, was Ihre Abfrage versucht, indem Sie sie verwenden. Das letzte, was Sie wollen, ist ein zukünftiger Betreuer Ihres Codes, der ihn wieder auf ein Gleichheitszeichen umstellt, da er keine Platzhalterzeichen sieht.
Eine weitere Option, die ich gesehen habe, besteht darin, zusätzlich zum Wertvergleich einen Datenlängenvergleich durchzuführen:

Diese Lösung ist jedoch nicht für jedes Szenario geeignet., Für den Anfang haben Sie keine Möglichkeit zu wissen, ob SQL Server zuerst Ihren Wertvergleich oder das DATALENGTH-Prädikat ausführt. Dies könnte die Indexnutzung beeinträchtigen und zu einer schlechten Leistung führen.
Ein schwerwiegenderes Problem kann auftreten, wenn Sie Felder mit verschiedenen Datentypen vergleichen., Wenn Sie beispielsweise einen VARCHAR mit einem NVARCHAR Datentyp vergleichen, ist es ziemlich einfach, ein Szenario zu erstellen, in dem Ihre Vergleichsabfrage mit DATALENGTH ein falsch positives Ergebnis auslöst:

Hier speichert der NVARCHAR 2 Bytes für jedes Zeichen, wodurch die Datenlängen eines einzelnen Zeichens NVARCHAR gleich einem Zeichen + einem Leerzeichen VARCHAR Wert.
Das Beste, was Sie in diesen Szenarien tun können, ist, Ihre Daten zu verstehen und eine Lösung auszuwählen, die für Ihre spezielle Situation geeignet ist.,
Und vielleicht schneiden Sie Ihre Daten vor dem Einfügen (wenn es sinnvoll ist)!















