Espaces de fin dans SQL Server
regardez la vidéo de cette semaine sur YouTube
Il y a longtemps, j’ai construit une application qui capturait l’entrée de l’utilisateur. Une des caractéristiques de la demande était de comparer l’entrée de l’utilisateur sur une base de données de valeurs.
l’application a effectué cette comparaison de texte dans le cadre d’une procédure stockée SQL Server, me permettant de mettre à jour facilement la logique métier à l’avenir si nécessaire.
Un jour, j’ai reçu un e-mail d’un utilisateur disant que la valeur qu’ils tapaient correspondait à une valeur de base de données qu’ils savaient ne pas correspondre., C’est le jour où j’ai découvert la comparaison d’égalité contre-intuitive de SQL Server lors du traitement des caractères d’espace de fin.
espace blanc rembourré
Vous savez probablement que le type de données CHAR remplit la valeur d’espaces jusqu’à ce que la longueur définie soit atteinte:
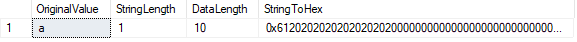
la fonction LEN() indique le nombre de caractères dans notre chaîne, tandis que la fonction DATALENGTH() nous indique le nombre
dans ce cas, DATALENGTH est égal à 10., Ce résultat est dû aux espaces capitonnés se produisant après le caractère « a » afin de remplir la longueur de caractère définie de 10. Nous pouvons le confirmer en convertissant la valeur en hexadécimal. Nous voyons la valeur 61 (« a « en hexadécimal) suivie de neuf valeurs » 20 » (espaces).
Si nous changeons le type de données de notre variable en VARCHAR, nous verrons que la valeur n’est plus remplie d’espaces:

étant donné que l’un de ces types de données contient des valeurs avec des caractères d’espace alors que l’autre ne le fait pas, que se passe-t-il,
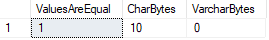
dans ce cas, SQL Server considère les deux valeurs égales, même si nous pouvons confirmer que les longueurs de données sont différentes.
ce comportement ne se produit cependant pas uniquement avec des comparaisons de types de données mixtes. Si nous comparons deux valeurs du même type de données, avec une valeur contenant plusieurs caractères d’espace, nous expérimentons quelque chose…inattendu:

même si nos deux variables ont des valeurs différentes (un vide par rapport à quatre caractères d’espace), SQL Server considère ces valeurs égales.,
Si nous ajoutons un caractère avec des espaces de fin, nous verrons le même comportement:

Les deux valeurs sont clairement différentes, mais SQL Server les considère comme égales les unes aux autres. Passer notre signe égal à un opérateur LIKE change légèrement les choses:

même si je pense qu’un LIKE sans caractères génériques se comporterait comme un signe égal, SQL Server n’effectue pas ces comparaisons de la même manière.,
Si nous revenons à notre comparaison de signes égaux et préfixons notre valeur de caractère avec des espaces, nous remarquerons également un résultat différent:

SQL Server considère deux valeurs égales indépendamment des espaces se produisant à la fin d’une chaîne. Les espaces précédant une chaîne ne sont cependant plus considérés comme une correspondance.
Ce qui se passe?
ANSI
bien que contre-intuitif, la fonctionnalité de SQL Server est justifiée., SQL Server suit la spécification ANSI pour comparer les chaînes, en ajoutant des espaces blancs aux chaînes afin qu’elles aient la même longueur Avant de les comparer. Cela explique les phénomènes que nous voyons.
il ne le fait cependant pas avec L’opérateur LIKE, ce qui explique la différence de comportement.
comparaisons lorsque les espaces supplémentaires sont importants
disons que nous voulons faire une comparaison où la différence dans les espaces de fin est importante.
Une option est d’utiliser l’opérateur LIKE comme nous l’avons vu quelques exemples., Ce n’est cependant pas l’utilisation typique de L’opérateur LIKE, alors assurez-vous de commenter et d’expliquer ce que votre requête tente de faire en l’utilisant. La dernière chose que vous voulez est qu’un futur mainteneur de votre code le ramène à un signe égal car il ne voit aucun caractère générique.
Une autre option que j’ai vue consiste à effectuer une comparaison de longueur de données en plus de la comparaison de valeurs:

Cette solution n’est cependant pas adaptée à tous les scénarios., Pour commencer, vous n’avez aucun moyen de savoir si SQL Server exécutera d’abord votre comparaison de valeurs ou votre prédicat DATALENGTH. Cela pourrait faire des ravages sur l’utilisation de l’index et entraîner de mauvaises performances.
un problème plus grave peut survenir si vous comparez des champs avec différents types de données., Par exemple, lorsque vous comparez un type de données varchar à NVARCHAR, il est assez facile de créer un scénario où votre requête de comparaison utilisant DATALENGTH déclenchera un faux positif:

ici, NVARCHAR stocke 2 octets pour chaque caractère, ce qui fait que les longueurs de données d’un seul caractère NVARCHAR sont égales à
La meilleure chose à faire dans ces scénarios est de comprendre vos données et de choisir une solution qui fonctionne pour votre situation particulière.,
et peut-être couper vos données avant l’insertion (si cela a du sens de le faire)!















