K-voisins les plus proches: qui sont proches de vous?
Si vous allez à l’université, vous avez probablement participé à au moins deux organisations étudiantes. Je commence mon 1er semestre en tant qu’étudiant diplômé à Rochester Tech, et il y a plus de 350 organisations ici. Ils sont classés en différentes catégories en fonction des intérêts de l’étudiant. Qu’est-ce qui définit ces catégories et qui dit quelle organisation entre dans quelle catégorie? Je suis sûr que si vous demandiez aux personnes qui dirigent ces organisations, elles ne diraient pas que leur organisation ressemble à celle de quelqu’un d’autre, mais d’une certaine manière, vous savez qu’elles sont similaires., Fraternités et sororités ont le même intérêt pour la vie grecque. Le football intra-muros et le tennis en club ont le même intérêt pour le sport. Le Groupe Latino et le groupe américain D’origine asiatique ont le même intérêt pour la diversité culturelle. Peut-être que si vous mesuriez les événements et les réunions organisés par ces organisations, vous pourriez automatiquement déterminer à quelle catégorie appartient une organisation. Je vais utiliser les organisations d’étudiants pour expliquer certains des concepts de K-voisins les plus proches, sans doute l’algorithme d’apprentissage automatique le plus simple du marché. La construction du modèle consiste uniquement à stocker l’ensemble de données d’entraînement., Pour faire une prédiction pour un nouveau point de données, l’algorithme trouve les points de données les plus proches dans l’ensemble de données d’entraînement — ses « voisins les plus proches. »
comment cela fonctionne
dans sa version la plus simple, l’algorithme k-NN ne considère exactement qu’un voisin le plus proche, qui est le point de données d’entraînement le plus proche du point pour lequel nous voulons faire une prédiction. La prédiction est alors simplement la sortie connue pour ce point d’entraînement., La Figure ci-dessous illustre ceci pour le cas de la classification sur la forge de l’ensemble de données:

Ici, nous avons ajouté trois nouveaux points de données, montre que les étoiles. Pour chacun d’eux, nous avons marqué le point le plus proche de l’ensemble d’entraînement. La prédiction de l’algorithme du plus proche voisin est l’étiquette de ce point (représentée par la couleur de la Croix).
Au Lieu de considérer uniquement le voisin le plus proche, nous pouvons également considérer un nombre arbitraire, k, de voisins., C’est de là que vient le nom de l’algorithme DES K-voisins les plus proches. Lorsque nous considérons plus d’un voisin, nous utilisons le vote pour attribuer une étiquette. Cela signifie que pour chaque point d’essai, nous comptons combien de voisins appartiennent à la classe 0 et combien de voisins appartiennent à la classe 1. Nous attribuons ensuite la classe la plus fréquente: en d’autres termes, la classe majoritaire parmi les K-voisins les plus proches., L’exemple suivant utilise les cinq plus proches voisins:
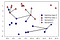
Encore une fois, la prédiction est montré que la couleur de la croix. Vous pouvez voir que la prédiction pour le nouveau point de données en haut à gauche n’est pas la même que la prédiction lorsque nous avons utilisé un seul voisin.
bien que cette illustration concerne un problème de classification binaire, cette méthode peut être appliquée à des ensembles de données avec n’importe quel nombre de classes., Pour plus de classes, nous comptons le nombre de voisins appartenant à chaque classe et prédisons à nouveau la classe la plus commune.,ordre d’assouplissement
le code Python de la fonction est ici:
creusons un peu plus profondément dans le code:
- la fonction knnclassify prend 4 entrées: le vecteur d’entrée à classer appelé a, une matrice complète D’exemples de formation appelée dataset, un vecteur d’étiquettes appelé labels, et K — le nombre de voisins les plus proches à utiliser dans le vote., Le vecteur étiquettes doit contenir autant d’éléments qu’il y a de lignes dans la matrice de l’ensemble de données.
- nous calculons les distances entre A et le point courant en utilisant la distance euclidienne.
- Ensuite, nous trions les distances dans un ordre croissant.
- ensuite, les K distances les plus basses sont utilisées pour voter sur la classe de A.
- après cela, nous prenons le dictionnaire classCount et le décomposons en une liste de tuples, puis trions les tuples par le 2ème élément du tuple. Le tri se fait en sens inverse, nous avons donc le plus grand au plus petit.,
- enfin, nous retournons l’étiquette de l’article qui se produit le plus fréquemment.
implémentation via Scikit-Learn
voyons maintenant comment implémenter l’algorithme kNN en utilisant scikit-learn:
examinons le code:
- tout d’abord, nous générons le jeu de données Iris.
- ensuite, nous avons divisé nos données en un ensemble de formation et de tests pour évaluer les performances de généralisation.
- ensuite, nous spécifions le nombre de voisins (k) à 5.
- ensuite, nous ajustons le classificateur à l’aide de l’ensemble d’entraînement.,
- Pour faire des prédictions sur les données de test, nous appelons le prédire méthode. Pour chaque point de données de l’ensemble de tests, la méthode calcule ses voisins les plus proches dans l’ensemble de formation et trouve la classe la plus commune parmi eux.
- enfin, nous évaluons la façon dont notre modèle se généralise en appelant la méthode score avec des données de test et des étiquettes de test.
L’exécution du modèle devrait nous donner une précision d’ensemble de test de 97%, ce qui signifie que le modèle a prédit correctement la classe pour 97% des échantillons de l’ensemble de données de test.,

les points Forts et les Faiblesses
En principe, il y a deux paramètres importants pour la KNeighbors classificateur: le nombre de voisins et de la façon dont vous mesurez la distance entre les points de données.
- En pratique, l’utilisation d’un petit nombre de voisins comme trois ou cinq fonctionne souvent bien, mais vous devez certainement ajuster ce paramètre.
- choisir la bonne mesure de distance est quelque peu délicat., Par défaut, la distance euclidienne est utilisée, ce qui fonctionne bien dans de nombreux paramètres.
l’Un des points forts de k-NN est que le modèle est très facile à comprendre, et donne souvent de rendement raisonnables, sans beaucoup d’ajustements. L’utilisation de cet algorithme est une bonne méthode de base à essayer avant d’envisager des techniques plus avancées. La construction du modèle de voisins les plus proches est généralement très rapide, mais lorsque votre ensemble d’entraînement est très grand (en nombre de fonctionnalités ou en nombre d’échantillons), la prédiction peut être lente. Lorsque vous utilisez l’algorithme k-NN, il est important de prétraiter vos données., Cette approche ne fonctionne souvent pas bien sur les ensembles de données avec de nombreuses fonctionnalités (des centaines ou plus), et elle le fait particulièrement mal avec les ensembles de données où la plupart des fonctionnalités sont 0 la plupart du temps (ensembles de données dits clairsemés).
en Conclusion
l’algorithme DES K-voisins les plus proches est un moyen simple et efficace de classer les données. C’est un exemple d’apprentissage basé sur les instances, où vous devez avoir des instances de données à portée de main pour exécuter l’algorithme d’apprentissage automatique. L’algorithme doit transporter l’ensemble de données complet; pour les grands ensembles de données, cela implique une grande quantité de stockage., En outre, vous devez calculer la mesure de distance pour chaque élément de données de la base de données, ce qui peut être fastidieux. Un inconvénient supplémentaire est que kNN ne vous donne aucune idée de la structure sous-jacente des données; vous n’avez aucune idée de ce à quoi ressemble une instance « moyenne” ou « exemplaire” de chaque classe.
ainsi, alors que l’algorithme DES K-voisins les plus proches est facile à comprendre, il n’est pas souvent utilisé dans la pratique, en raison de la lenteur de la prédiction et de son incapacité à gérer de nombreuses fonctionnalités.,
sources de référence:
- L’apprentissage automatique en Action par Peter Harrington (2012)
- Introduction à L’apprentissage automatique avec Python par Sarah Guido et Andreas Muller (2016)















