k-Dichtstbijzijnde buren: wie zijn dicht bij u?
als je naar de universiteit gaat, heb je waarschijnlijk deelgenomen aan ten minste een paar studentenorganisaties. Ik begin mijn eerste semester als afgestudeerde student aan Rochester Tech, en er zijn meer dan 350 organisaties hier. Ze worden gesorteerd in verschillende categorieën op basis van de belangen van de student. Wat definieert deze categorieën, en wie zegt welke org gaat in welke categorie? Ik weet zeker dat als je het de mensen die deze organisaties leiden zou vragen, ze niet zouden zeggen dat hun org net als de org van iemand anders is, maar op de een of andere manier weet je dat ze vergelijkbaar zijn., Broederschappen en sociëteiten hebben dezelfde interesse in het Griekse leven. Intramurale voetbal en club tennis hebben dezelfde interesse in sport. De Latino-groep en de Aziatisch-Amerikaanse groep hebben dezelfde belangstelling voor culturele diversiteit. Misschien als je de evenementen en bijeenkomsten van deze organisaties zou meten, zou je automatisch kunnen achterhalen tot welke categorie een organisatie behoort. Ik zal studentenorganisaties gebruiken om enkele van de concepten uit te leggen van k-Dichtstbijzijnde buren, misschien wel het eenvoudigste machine learning algoritme dat er is. Het bouwen van het model bestaat alleen uit het opslaan van de trainingsdataset., Om een voorspelling te maken voor een nieuw datapunt, het algoritme vindt de dichtstbijzijnde datapunten in de training dataset — de “dichtstbijzijnde buren.”
hoe het werkt
in zijn eenvoudigste versie beschouwt het k-NN algoritme slechts één naaste buur, dat is het dichtstbijzijnde trainingsgegevenspunt naar het punt waarvoor we een voorspelling willen maken. De voorspelling is dan gewoon de bekende output voor dit trainingspunt., Figuur hieronder illustreert dit voor het geval van classificatie op de forge dataset:

Hier hebben we drie nieuwe gegevenspunten toegevoegd, weergegeven als sterren. Voor elk van hen markeerden we het dichtstbijzijnde punt in de trainingsset. De voorspelling van het een-dichtstbijzijnde-buurman algoritme is het label van dat punt (getoond door de kleur van het kruis).
in plaats van alleen de naaste buur te beschouwen, kunnen we ook een willekeurig aantal, k, buren overwegen., Hier komt de naam van het algoritme van de dichtstbijzijnde buren vandaan. Wanneer we meer dan één buurman overwegen, gebruiken we stemmen om een label toe te wijzen. Dit betekent dat we voor elk testpunt tellen hoeveel buren behoren tot klasse 0 en hoeveel buren behoren tot klasse 1. We wijzen dan de klasse toe die vaker voorkomt: met andere woorden, de meerderheidsklasse onder de k-dichtstbijzijnde buren., Het volgende voorbeeld gebruikt de vijf naaste buren:
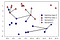
opnieuw wordt de voorspelling weergegeven als de kleur van het kruis. Je kunt zien dat de voorspelling voor het nieuwe gegevenspunt linksboven niet hetzelfde is als de voorspelling toen we slechts één buurman gebruikten.
hoewel deze illustratie voor een binair classificatieprobleem is, kan deze methode worden toegepast op datasets met een willekeurig aantal klassen., Voor meer klassen tellen we hoeveel buren tot elke klasse behoren en voorspellen we opnieuw de meest voorkomende klasse.,de versoepeling van de order
De Python-code voor de functie is hier:
Laten we graven een beetje dieper in de code:
- De functie knnclassify duurt 4 ingangen: de input vector te classificeren genoemd, een volledige matrix van de opleiding voorbeelden genoemd dataSet, een vector van labels genoemd etiketten, en k — het nummer van de dichtstbijzijnde buren om te gebruiken in de stemming., De labels vector moet zoveel elementen bevatten als er rijen zijn in de dataset matrix.
- we berekenen de afstanden tussen A en het huidige punt met behulp van de Euclidische afstand.
- dan Sorteren we de afstanden in toenemende volgorde.
- vervolgens worden de laagste K afstanden gebruikt om te stemmen op de klasse van A.
- daarna nemen we het classCount woordenboek en ontbinden het in een lijst met tupels en sorteren de tupels op het tweede item in de tupel. De sortering gebeurt in omgekeerde volgorde, dus we hebben de grootste tot kleinste.,
- ten slotte retourneren we het label van het item dat het vaakst voorkomt.
implementatie Via Scikit-Learn
laten we nu eens kijken hoe we het KNN-algoritme kunnen implementeren met behulp van scikit-learn:
laten we eens kijken naar de code:
- eerst genereren we de iris-dataset.
- vervolgens splitsen we onze gegevens op in een trainings-en testset om de generalisatieprestaties te evalueren.
- vervolgens specificeren we het aantal buren (k) tot 5.
- vervolgens passen we de classifier aan met behulp van de trainingsset.,
- om voorspellingen te doen op de testgegevens noemen we de predict methode. Voor elk gegevenspunt in de testset berekent de methode de dichtstbijzijnde buren in de trainingsset en vindt de meest voorkomende klasse onder hen.
- ten slotte evalueren we hoe goed Ons model generaliseert door de scoremethode aan te roepen met testgegevens en testlabels.
het uitvoeren van het model geeft ons een nauwkeurigheid van de testset van 97%, wat betekent dat het model de klasse correct voorspelde voor 97% van de monsters in de testdataset.,

de Sterke en Zwakke punten
In principe zijn er twee belangrijke parameters om de KNeighbors classifier: het aantal buren en hoe meet u de afstand tussen de meetpunten.
- in de praktijk werkt het gebruik van een klein aantal buren zoals drie of vijf vaak goed, maar je moet deze parameter zeker aanpassen.
- het kiezen van de juiste afstandsmaat is enigszins lastig., Standaard wordt Euclidische afstand gebruikt, wat in veel instellingen goed werkt.
een van de sterke punten van k-NN is dat het model zeer gemakkelijk te begrijpen is en vaak redelijke prestaties levert zonder veel aanpassingen. Met behulp van dit algoritme is een goede basislijn methode om te proberen alvorens meer geavanceerde technieken te overwegen. Het bouwen van de dichtstbijzijnde buren model is meestal erg snel, maar wanneer uw training set is zeer groot (hetzij in aantal functies of in aantal monsters) voorspelling kan traag zijn. Bij het gebruik van het k-NN algoritme is het belangrijk om uw gegevens vooraf te verwerken., Deze aanpak presteert vaak niet goed op datasets met veel functies (honderden of meer), en doet het vooral slecht met datasets waar de meeste functies meestal 0 zijn (zogenaamde sparse datasets).
concluderend
het algoritme k-Dichtstbijzijnde buren is een eenvoudige en effectieve manier om gegevens te classificeren. Het is een voorbeeld van instance-based learning, waar je nodig hebt om instanties van gegevens bij de hand om de machine learning algoritme uit te voeren. Het algoritme moet de volledige dataset ronddragen; voor grote datasets impliceert dit een grote hoeveelheid opslag., Bovendien moet u de afstandsmeting voor elk stukje gegevens in de database berekenen en dit kan omslachtig zijn. Een bijkomend nadeel is dat kNN je geen idee geeft van de onderliggende structuur van de gegevens; Je hebt geen idee hoe een “gemiddelde” of “voorbeeld” instantie van elke klasse eruit ziet.
dus, hoewel het dichtstbijzijnde K-buren algoritme gemakkelijk te begrijpen is, wordt het niet vaak gebruikt in de praktijk, vanwege de trage voorspelling en het onvermogen om veel functies te hanteren.,
referentiebronnen:
- Machine Learning in Action door Peter Harrington (2012)
- Inleiding tot Machine Learning met Python door Sarah Guido en Andreas Muller (2016)















