K-najbliżsi sąsiedzi: kto jest blisko ciebie?
jeśli chodzisz na studia, prawdopodobnie brałeś udział w co najmniej kilku organizacjach studenckich. Rozpoczynam pierwszy semestr jako absolwent Rochester Tech i jest tu ponad 350 organizacji. Są one posortowane w różnych kategoriach w zależności od zainteresowań ucznia. Co definiuje te kategorie i kto mówi, która organizacja wchodzi do jakiej kategorii? Jestem pewien, że gdybyś zapytał ludzi prowadzących te organizacje, nie powiedzieliby, że ich org jest tak samo jak czyjeś orgie, ale w pewien sposób wiesz, że są podobne., Bractwa i Bractwa mają takie samo zainteresowanie greckim życiem. Piłka nożna i tenis klubowy mają takie samo zainteresowanie sportem. Grupa latynoamerykańska i grupa Azjatycka mają takie samo zainteresowanie różnorodnością kulturową. Być może, gdybyś zmierzył wydarzenia i spotkania prowadzone przez te organizacje, mógłbyś automatycznie dowiedzieć się, do jakiej kategorii należy dana organizacja. Użyję organizacji studenckich do wyjaśnienia niektórych pojęć K-najbliżsi sąsiedzi, prawdopodobnie najprostszy algorytm uczenia maszynowego tam. Budowanie modelu polega wyłącznie na przechowywaniu zbioru danych treningowych., Aby przewidzieć nowy punkt danych, algorytm znajduje najbliższe punkty danych w zbiorze danych treningowych — jego ” najbliższych sąsiadów.”
Jak to działa
w najprostszej wersji algorytm k-NN uwzględnia tylko jednego najbliższego sąsiada, czyli najbliższy punkt danych treningowych do punktu, dla którego chcemy dokonać prognozy. Przewidywanie jest wtedy po prostu znanym wynikiem dla tego punktu treningowego., Poniższy rysunek ilustruje to dla przypadku klasyfikacji na zbiorze danych forge:

tutaj dodaliśmy trzy nowe punkty danych, pokazane jako gwiazdki. Dla każdego z nich zaznaczyliśmy najbliższy punkt w zestawie treningowym. Przewidywanie algorytmu jeden-najbliższy-sąsiad jest etykietą tego punktu (pokazaną przez kolor krzyża).
zamiast brać pod uwagę tylko najbliższego sąsiada, możemy również rozważyć dowolną liczbę, k, sąsiadów., Stąd pochodzi nazwa algorytmu K-najbliższych sąsiadów. Rozważając więcej niż jednego sąsiada, używamy głosowania, aby przypisać Etykietę. Oznacza to, że dla każdego punktu testowego liczymy, ilu sąsiadów należy do klasy 0, a ilu sąsiadów należy do klasy 1. Następnie przypisujemy klasę, która jest częstsza: innymi słowy, klasę większości wśród K-najbliższych sąsiadów., Poniższy przykład używa pięciu najbliższych sąsiadów:
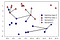
Widać, że przewidywanie nowego punktu danych w lewym górnym rogu nie jest takie samo jak przewidywanie, gdy użyliśmy tylko jednego sąsiada.
chociaż ta ilustracja dotyczy problemu klasyfikacji binarnej, ta metoda może być stosowana do zbiorów danych z dowolną liczbą klas., W przypadku większej liczby klas liczymy, ilu sąsiadów należy do każdej klasy i ponownie przewidujemy najczęściej spotykaną klasę.,łatwiejsza kolejność
Kod Pythona dla funkcji znajduje się tutaj:
zagłębimy się nieco głębiej w kod:
- funkcja knnclassify pobiera 4 wejścia: wektor wejściowy do klasyfikacji zwany a, pełną macierz przykładów szkoleniowych zwanych dataset, wektor etykiet zwany etykietami oraz K — liczbę najbliższych sąsiadów, których można użyć w głosowaniu., Wektor etykiet powinien mieć w sobie tyle elementów, ile jest wierszy w macierzy zbioru danych.
- obliczamy odległości między A A aktualnym punktem używając odległości euklidesowej.
- następnie sortujemy odległości w rosnącej kolejności.
- następnie najniższe odległości k są używane do głosowania na klasę A.
- następnie bierzemy słownik classCount i rozkładamy go na listę krotek, a następnie sortujemy krotki według 2 pozycji w krotce. Sortowanie odbywa się na odwrót, więc mamy największy do najmniejszego.,
- na koniec zwracamy Etykietę elementu występującego najczęściej.
implementacja za pomocą Scikit-Learn
teraz przyjrzyjmy się, jak możemy zaimplementować algorytm kNN za pomocą scikit-learn:
przyjrzyjmy się kodowi:
- najpierw generujemy zbiór danych Iris.
- następnie dzielimy nasze dane na treningowe i testowe, aby ocenić wydajność uogólniania.
- następnie określamy liczbę sąsiadów (k) na 5.
- następnie dopasowujemy klasyfikator za pomocą zestawu treningowego.,
- aby przewidywać dane testowe, nazywamy metodę predict. Dla każdego punktu danych w zestawie testowym metoda oblicza swoich najbliższych sąsiadów w zestawie treningowym i wyszukuje najczęstszą klasę spośród nich.
- na koniec oceniamy, jak dobrze uogólnia się nasz model, wywołując metodę score z danymi testowymi i etykietami testowymi.
uruchomienie modelu powinno dać nam dokładność zestawu testowego 97%, co oznacza, że model prawidłowo przewidział klasę dla 97% próbek w zestawie danych testowych.,

mocne i słabe strony
zasadniczo klasyfikator kneighbors ma dwa ważne parametry: liczbę sąsiadów i sposób pomiaru odległości między punktami danych.
- w praktyce korzystanie z małej liczby sąsiadów jak trzy lub pięć często działa dobrze, ale na pewno należy dostosować ten parametr.
- wybór właściwej miary odległości jest nieco trudny., Domyślnie używana jest odległość euklidesowa, która działa dobrze w wielu ustawieniach.
jedną z mocnych stron k-NN jest to, że model jest bardzo łatwy do zrozumienia i często daje rozsądną wydajność bez wielu regulacji. Korzystanie z tego algorytmu jest dobrą metodą bazową, aby wypróbować przed rozważeniem bardziej zaawansowanych technik. Budowanie modelu najbliższego sąsiada jest zwykle bardzo szybkie, ale gdy zestaw treningowy jest bardzo duży (w liczbie funkcji lub w liczbie próbek) przewidywanie może być powolne. Podczas korzystania z algorytmu k-NN ważne jest, aby wstępnie przetworzyć dane., Takie podejście często nie działa dobrze na zestawach danych z wieloma funkcjami (setkami lub więcej), i robi to szczególnie źle z zestawami danych, w których większość funkcji jest 0 przez większość czasu (tak zwane rzadkie zestawy danych).
Podsumowując
algorytm K-najbliższych sąsiadów jest prostym i skutecznym sposobem klasyfikacji danych. Jest to przykład uczenia się opartego na instancjach, gdzie instancje danych muszą być pod ręką, aby wykonać algorytm uczenia maszynowego. Algorytm musi przenosić cały zbiór danych; w przypadku dużych zbiorów danych oznacza to dużą ilość miejsca na dysku., Ponadto musisz obliczyć pomiar odległości dla każdego fragmentu danych w bazie danych, co może być uciążliwe. Dodatkową wadą jest to, że kNN nie daje żadnego pojęcia o podstawowej strukturze danych; nie masz pojęcia, jak wygląda” średnia „lub” przykładowa ” instancja z każdej klasy.
tak więc, chociaż najbliższy algorytm k-neighbors jest łatwy do zrozumienia, nie jest często używany w praktyce, ze względu na powolne przewidywanie i jego niezdolność do obsługi wielu funkcji.,
źródła odniesienia:
- Uczenie maszynowe w działaniu Peter Harrington (2012)
- Wprowadzenie do uczenia maszynowego z Pythonem Sarah Guido i Andreas Muller (2016)















