Spacje końcowe w SQL Server
obejrzyj ten filmik na YouTube
dawno temu zbudowałem aplikację, która przechwyciła dane użytkownika. Jedną z cech aplikacji było porównanie danych wejściowych użytkownika z bazą danych wartości.
aplikacja wykonała to porównanie tekstu w ramach procedury składowanej SQL Server, co pozwoliło mi łatwo zaktualizować logikę biznesową w przyszłości, jeśli to konieczne.
pewnego dnia otrzymałem wiadomość e-mail od użytkownika, że wartość, którą wpisywał, pasowała do wartości bazy danych, o której wiedział, że nie powinna pasować., To dzień, w którym odkryłem intuicyjne porównanie równości SQL Server, gdy mamy do czynienia z końcowymi znakami spacji.
Wyściełana Biała spacja
prawdopodobnie wiesz, że typ danych CHAR blokuje wartość spacjami aż do osiągnięcia określonej długości:
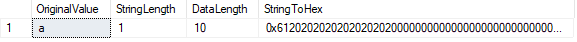
funkcja LEN() pokazuje liczbę znaków w naszym łańcuchu, podczas gdy funkcja DATALENGTH() pokazuje liczbę bajtów używanych przez ten łańcuch.
w tym przypadku długość danych jest równa 10., Wynik ten wynika z wypełnionych spacji występujących po znaku ” a ” w celu wypełnienia zdefiniowanej długości znaku 10. Możemy to potwierdzić, zamieniając wartość na szesnastkową. Widzimy wartość 61 („a” w hex), a następnie dziewięć wartości ” 20 ” (spacje).
jeśli zmienimy typ danych naszej zmiennej na VARCHAR, zobaczymy, że wartość nie jest już wypełniona spacjami:

biorąc pod uwagę, że jeden z tych typów danych blokuje wartości ze znakami spacji, a drugi nie, co się stanie, jeśli porównamy te dwa?,
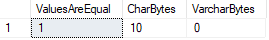
w tym przypadku SQL Server uznaje obie wartości za równe, chociaż możemy potwierdzić, że długość danych jest inna.
to zachowanie występuje nie tylko w przypadku porównań mieszanych typów danych. Jeśli porównamy dwie wartości tego samego typu danych, z jedną wartością zawierającą kilka znaków spacji, doświadczamy czegoś…unexpected:

mimo że nasze dwie zmienne mają różne wartości (puste w porównaniu do czterech znaków spacji), SQL Server uważa te wartości za równe.,
jeśli dodamy znak z końcowymi białymi spacjami, zobaczymy to samo zachowanie:

obie wartości są wyraźnie różne, ale SQL Server uważa je za równe sobie. Przełączenie naszego znaku równości na operatora LIKE zmienia nieco rzeczy:

mimo że myślałem, że podobny bez znaków wieloznacznych zachowywałby się tak jak znak równości, SQL Server nie wykonuje tych porównań w ten sam sposób.,
Jeśli przełączymy się z powrotem do porównania znaku równości i poprzedzimy naszą wartość znakiem ze spacjami, zauważymy również inny wynik:

SQL Server uważa dwie wartości za równe, niezależnie od spacji występujących na końcu łańcucha. Spacje poprzedzające ciąg znaków nie są już jednak uznawane za dopasowanie.
O co chodzi?
ANSI
chociaż licznik intuicyjny, funkcjonalność SQL Servera jest uzasadniona., SQL Server stosuje specyfikację ANSI do porównywania łańcuchów, dodając do łańcuchów białą spację, aby były tej samej długości przed porównaniem. To wyjaśnia zjawiska, które widzimy.
nie robi tego jednak z operatorem LIKE, co wyjaśnia różnicę w zachowaniu.
porównania, gdy dodatkowe spacje mają znaczenie
powiedzmy, że chcemy zrobić porównanie, w którym różnica w spacjach końcowych ma znaczenie.
jedną z opcji jest użycie operatora LIKE, ponieważ widzieliśmy kilka przykładów wstecz., Nie jest to jednak typowe użycie operatora LIKE, więc pamiętaj, aby skomentować i wyjaśnić, co twoje zapytanie próbuje zrobić, używając go. Ostatnią rzeczą, jakiej chcesz, to przyszły opiekun Twojego kodu, który przełączy go z powrotem na znak równości, ponieważ nie widzi żadnych znaków z dzikimi kartami.
inną opcją, którą widziałem, jest wykonanie porównania długości danych oprócz porównania wartości:

To rozwiązanie nie jest odpowiednie dla każdego scenariusza., Na początek nie masz możliwości sprawdzenia, czy SQL Server wykona najpierw porównanie wartości lub predykat DATALENGTH. Może to zniszczyć spustoszenie w użyciu indeksów i spowodować słabą wydajność.
poważniejszy problem może wystąpić, jeśli porównujesz pola z różnymi typami danych., Na przykład, podczas porównywania typu danych VARCHAR z typem danych NVARCHAR, bardzo łatwo jest stworzyć scenariusz, w którym zapytanie porównawcze przy użyciu DATALENGTH wywoła fałszywie dodatni wynik:

tutaj NVARCHAR przechowuje 2 bajty dla każdego znaku, powodując, że długość danych pojedynczego znaku NVARCHAR jest równa wartości znaku + spacji VARCHAR.
najlepszą rzeczą do zrobienia w tych scenariuszach jest zrozumienie danych i wybór rozwiązania, które będzie działać w danej sytuacji.,
i może przyciąć dane przed wstawieniem(jeśli ma to sens)!















