Efterfølgende mellemrum i S .l Server
se denne uges video på YouTube
for længe siden byggede jeg et program, der fangede brugerinput. Et træk ved ansøgningen var at sammenligne brugerens input mod en database af værdier.
appen udførte denne tekstsammenligning som en del af en s .l Server-gemt procedure, så jeg nemt kan opdatere forretningslogikken i fremtiden, hvis det er nødvendigt. en dag modtog jeg en e-mail fra en bruger, der sagde, at den værdi, de indtastede, matchede med en databaseværdi, som de vidste ikke skulle matche., Det er den dag, jeg opdagede s .l Server ‘ s counter intuitive ligestillingssammenligning, når jeg beskæftiger mig med efterfølgende rumkarakterer.
Polstret, hvid
Du er sikkert klar over, at det CHAR data type puder værdien med mellemrum, indtil den fastlagte længde er nået:
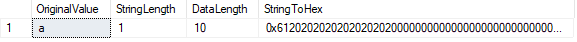
LEN() funktion viser antallet af tegn i vores streng, mens DATALENGTH() funktion, der viser det antal byte, der bruges af den pågældende streng.
i dette tilfælde er DATALÆNGDEN er lig med 10., Dette resultat skyldes de polstrede mellemrum, der forekommer efter tegnet ” a ” for at udfylde den definerede KARLÆNGDE på 10. Vi kan bekræfte dette ved at konvertere værdien til HE .adecimal. Vi ser værdien 61 (“a “I he.) efterfulgt af ni” 20 ” værdier (mellemrum).
Hvis vi ændrer vores variabel ‘ s data type VARCHAR, vi vil se værdien ikke længere er polstret med mellemrum:

i Betragtning af, at en af disse data typer puder værdier med mellemrum, mens andre ikke gør det, hvad sker der, hvis vi sammenligner de to?,
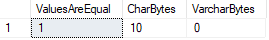
i dette tilfælde betragter s .l Server begge værdier ens, selvom vi kan bekræfte, at Datalængderne er forskellige.
denne adfærd ikke kun forekomme med blandede datatype sammenligninger dog. Hvis vi sammenligner to værdier af samme datatype, med en værdi, der indeholder flere rumtegn, oplever vi noget…uventet:

selvom vores to variabler har forskellige værdier (et tomt sammenlignet med fire rumtegn), betragter s .l Server disse værdier som ens.,
Hvis vi tilføjer en karakter med nogle trailing whitespace vil vi se den samme adfærd:

Begge værdier er klart forskellige, men SQL Server anser dem for at være lig med hinanden. Skifte vores lighedstegn til en SOM operatør ændrer lidt på tingene:

Selv om jeg ville synes, at en LIGNENDE uden jokertegn ville opføre sig ligesom et lighedstegn, SQL Server ikke udføre disse sammenligninger samme måde.,
Hvis vi skifter tilbage til vores lighedstegn sammenligning og præfiks vores karakterværdi med mellemrum, vil vi også bemærke et andet resultat:

s .l Server betragter to værdier ens uanset mellemrum, der forekommer i slutningen af en streng. Mellemrum forud for en streng dog ikke længere betragtes som en kamp.
Hvad sker der?
ANSI
mens counter intuitiv, s .l Server funktionalitet er berettiget., S .l Server følger ANSI-specifikationen til sammenligning af strenge og tilføjer hvidt rum til strenge, så de har samme længde, før de sammenlignes. Dette forklarer de fænomener, vi ser.
det gør det ikke med den samme operatør, hvilket forklarer forskellen i adfærd.
sammenligninger, når ekstra mellemrum betyder noget
lad os sige, at vi ønsker at foretage en sammenligning, hvor forskellen i efterfølgende rum betyder noget.
en mulighed er at bruge den samme operatør, da vi så et par eksempler tilbage., Dette er dog ikke den typiske brug af den lignende operatør, så sørg for at kommentere og forklare, hvad din forespørgsel forsøger at gøre ved at bruge den. Den sidste ting, du ønsker, er en fremtidig vedligeholder af din kode for at skifte den tilbage til et lige tegn, fordi de ikke ser nogen Joker-tegn.
en Anden mulighed, som jeg har set, er, at udføre en DATALENGTH sammenligning i tillæg til den værdi sammenligning:

Denne løsning er ikke det rigtige for hvert scenarie, dog., For startere, du har ingen måde at vide, om S .l Server vil udføre din værdi sammenligning eller DATALENGTH prædikat først. Dette kan ødelægge kaos på indeksforbrug og forårsage dårlig ydeevne.
et mere alvorligt problem kan opstå, hvis du sammenligner felter med forskellige datatyper., For eksempel, når man sammenligner en VARCHAR at datatype NVARCHAR, det er ret nemt at oprette en situation, hvor din sammenligning forespørgsel ved hjælp af DATALENGTH vil udløse en falsk positiv:

Her NVARCHAR butikker 2 bytes for hver karakter, hvilket DATALENGTHs af et enkelt tegn, NVARCHAR til at være lig med et tegn + en plads VARCHAR værdi.
den bedste ting at gøre i disse scenarier er at forstå dine data og vælge en løsning, der vil arbejde for netop din situation.,
og måske trimme dine data før indsættelse (hvis det giver mening at gøre det)!















