k-nærmeste naboer: Hvem er tæt på dig?
Hvis du går på college, har du sandsynligvis deltaget i mindst et par studenterorganisationer. Jeg starter mit 1. semester som kandidatstuderende ved Rochester Tech, og der er mere end 350 organisationer her. De er sorteret i forskellige kategorier baseret på den studerendes interesser. Hvad definerer disse kategorier, og hvem siger, hvilken org der går ind i hvilken kategori? Jeg er sikker på, at hvis du spurgte de mennesker, der driver disse organisationer, ville de ikke sige, at deres org er ligesom en andens org, men på en eller anden måde ved du, at de er ens., Broderskaber og sororiteter har samme interesse for det græske liv. Intramural fodbold-og klubtennis har samme interesse for sport. Latino-gruppen og den asiatiske amerikanske gruppe har samme interesse for kulturel mangfoldighed. Måske hvis du målte de begivenheder og møder, der drives af disse orgs, kunne du automatisk finde ud af, hvilken kategori en organisation tilhører. Jeg vil bruge studenterorganisationer til at forklare nogle af begreberne k-nærmeste naboer, uden tvivl den enkleste maskinlæringsalgoritme derude. Bygning modellen består kun af lagring af træningsdatasættet., For at lave en forudsigelse for et nyt datapunkt finder algoritmen de nærmeste datapunkter i træningsdatasættet — dets “nærmeste naboer.”
Sådan fungerer det
i sin enkleste version betragter k-nn-algoritmen kun nøjagtigt en nærmeste nabo, som er det nærmeste træningsdatapunkt til det punkt, vi ønsker at forudsige. Forudsigelsen er så simpelthen det kendte output for dette træningspunkt., Nedenstående figur illustrerer dette i tilfælde af klassificering på smede-datasæt:

Her, vi har tilføjet tre nye datapunkter, der vises som stjerner. For hver af dem markerede vi det nærmeste punkt i træningssættet. Forudsigelsen af den nærmeste nabo-algoritme er etiketten på det punkt (vist ved korsets farve).
i stedet for kun at overveje den nærmeste nabo, kan vi også overveje et vilkårligt antal, k, af naboer., Det er her navnet på den k-nærmeste nabo algoritme kommer fra. Når vi overvejer mere end en nabo, bruger vi afstemning til at tildele en etiket. Dette betyder, at vi for hvert testpunkt tæller, hvor mange naboer der hører til klasse 0, og hvor mange naboer der hører til klasse 1. Vi tildeler derefter den klasse, der er hyppigere: med andre ord, majoritetsklassen blandt k-nærmeste naboer., Det følgende eksempel bruger de fem nærmeste naboer:
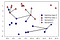
Igen, den forudsigelse er vist som farven på korset. Du kan se, at forudsigelsen for det nye datapunkt øverst til venstre ikke er det samme som forudsigelsen, da vi kun brugte en nabo.
mens denne illustration er til et binært klassifikationsproblem, kan denne metode anvendes på datasæt med et hvilket som helst antal klasser., For flere klasser tæller vi, hvor mange naboer der tilhører hver klasse og igen forudsiger den mest almindelige klasse.,lempelser for
Python-kode for funktionen er her:
Lad os grave lidt dybere i koden:
- funktion knnclassify tager 4 input: input vektor til at klassificere hedder En, en fuld matrix af uddannelse eksempler kaldet datasæt en vektor af etiketter, kaldet etiketter, og k — antallet af nærmeste naboer til brug i afstemninger., Etiketvektoren skal have så mange elementer i den, som der er rækker i datasætmatri .en.
- Vi beregner afstandene mellem A og det aktuelle punkt ved hjælp af den euklidiske afstand.
- så sorterer vi afstandene i stigende rækkefølge.
- dernæst bruges de laveste k-afstande til at stemme om klassen af A.
- derefter tager vi classCount-ordbogen og nedbryder den til en liste over tupler og sorterer derefter tuplerne efter 2.punkt i tuplen. Den slags sker i omvendt, så vi har den største til mindste.,
- endelig returnerer vi etiketten på den vare, der forekommer oftest.
Gennemførelsen Via Scikit-Lær
lad os Nu tage et kig på, hvordan vi kan gennemføre kNN algoritme, der anvender scikit-lære:
Lad os kigge i koden:
- Første, vi genererer iris-datasættet.
- derefter opdeler vi vores data i et trænings-og testsæt for at evaluere generaliseringsydelsen.
- dernæst angiver vi antallet af naboer (k) til 5.
- dernæst passer vi klassifikatoren ved hjælp af træningssættet.,
- for at forudsige testdataene kalder vi predict-metoden. For hvert datapunkt i testsættet beregner metoden sine nærmeste naboer i træningssættet og finder den mest almindelige klasse blandt dem.
- endelig vurderer vi, hvor godt vores model generaliserer ved at kalde scoringsmetoden med testdata og testetiketter.
kørsel af modellen skal give os en test sæt nøjagtighed på 97%, hvilket betyder, at modellen forudsagde klassen korrekt for 97% af prøverne i testdatasættet.,

Styrker og Svagheder
I princippet er der to vigtige parametre til KNeighbors klassificeringen: antallet af naboer, og hvordan du måle afstanden mellem datapunkter.
- i praksis fungerer det ofte godt at bruge et lille antal naboer som tre eller fem, men du bør bestemt justere denne parameter.
- det er noget vanskeligt at vælge den rigtige afstandsmåling., Som standard bruges euklidisk afstand, som fungerer godt i mange indstillinger.
en af styrkerne ved k-NN er, at modellen er meget let at forstå og ofte giver rimelig ydelse uden mange justeringer. Brug af denne algoritme er en god baseline metode til at prøve, før du overvejer mere avancerede teknikker. Opbygning af nærmeste naboer model er normalt meget hurtig, men når din uddannelse sæt er meget stor (enten i antal funktioner eller i antallet af prøver) forudsigelse kan være langsom. Når du bruger K-NN-algoritmen, er det vigtigt at forbehandle dine data., Denne tilgang fungerer ofte ikke godt på datasæt med mange funktioner (hundreder eller mere), og det gør især dårligt med datasæt, hvor de fleste funktioner er 0 det meste af tiden (såkaldte sparsomme datasæt).
afslutningsvis
k-nærmeste naboer algoritme er en enkel og effektiv måde at klassificere data. Det er et eksempel på eksempelbaseret læring, hvor du skal have forekomster af data tæt ved hånden for at udføre maskinlæringsalgoritmen. Algoritmen skal bære rundt på det fulde datasæt; for store datasæt indebærer dette en stor mængde opbevaring., Derudover skal du beregne afstandsmåling for hvert stykke data i databasen, og det kan være besværligt. En yderligere ulempe er, at kNN ikke giver dig nogen ID.om den underliggende struktur af dataene; du har ingen ID. om, hvordan en “gennemsnitlig” eller “eksemplar” – forekomst fra hver klasse ser ud.
så selvom den nærmeste k-naboer-algoritme er let at forstå, bruges den ikke ofte i praksis, fordi forudsigelse er langsom og dens manglende evne til at håndtere mange funktioner.,
Reference Kilder:
- Machine Learning I Handling af Peter Harrington (2012)
- Introduktion til Machine Learning med Python af Sarah Guido og Andreas Müller (2016)















