Espacios finales en SQL Server
Ver el video de esta semana en YouTube
hace mucho tiempo construí una aplicación que capturaba la entrada del usuario. Una característica de la aplicación era comparar la entrada del usuario con una base de datos de valores.
la aplicación realizó esta comparación de texto como parte de un procedimiento almacenado de SQL Server, lo que me permite actualizar fácilmente la lógica de negocio en el futuro si es necesario.
un día, recibí un correo electrónico de un usuario diciendo que el valor que estaban escribiendo coincidía con un valor de base de datos que sabían que no debía coincidir., Ese fue el día en que descubrí la comparación de igualdad contra-intuitiva de SQL Server cuando se trata de caracteres de espacio al final.
espacio en blanco acolchado
probablemente sepa que el tipo de datos CHAR rellena el valor con espacios hasta que se alcanza la longitud definida:
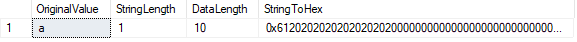
la función LEN() muestra el número de caracteres en nuestra cadena, mientras que la función DATALENGTH() nos muestra el número de bytes utilizados por esa cadena.
en este caso, DATALENGTH es igual a 10., Este resultado se debe a los espacios acolchados que aparecen después del carácter «a» con el fin de llenar la longitud de caracteres definida de 10. Podemos confirmar esto convirtiendo el valor a hexadecimal. Vemos el valor 61 («a» En hexadecimal) seguido de nueve valores «20» (espacios).
si cambiamos el tipo de datos de nuestra variable a VARCHAR, veremos que el valor ya no está rellenado con espacios:

dado que uno de estos tipos de datos rellena valores con caracteres de espacio mientras que el otro no, ¿qué sucede si comparamos los dos?,
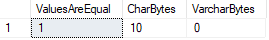
en este caso SQL Server considera ambos valores iguales, aunque podemos confirmar que los DATALENGTHs son diferentes.
sin embargo, este comportamiento no solo ocurre con comparaciones de tipos de datos mixtos. Si comparamos dos valores del mismo tipo de datos, con un valor que contiene varios caracteres de espacio, experimentamos algo…inesperado:

aunque nuestras dos variables tienen valores diferentes (un espacio en blanco comparado con cuatro caracteres de espacio), SQL Server considera que estos valores son iguales.,
si añadimos un carácter con algún espacio en blanco al final veremos el mismo comportamiento:

ambos valores son claramente diferentes, pero SQL Server los considera iguales entre sí. Cambiar nuestro signo igual a un operador ME GUSTA cambia las cosas ligeramente:

aunque pensaría que un Me gusta sin caracteres comodín se comportaría igual que un signo igual, SQL Server no realiza estas comparaciones de la misma manera.,
Si regresamos a nuestro signo igual la comparación y el prefijo de nuestro personaje valor con espacios que también notará un resultado diferente:

SQL Server considera dos valores iguales, independientemente de los espacios que ocurren al final de una cadena. Sin embargo, los espacios que preceden a una cadena ya no se consideran coincidentes.
¿Qué está pasando?
ANSI
aunque es contrario a lo intuitivo, la funcionalidad de SQL Server está justificada., SQL Server sigue la especificación ANSI para comparar cadenas, agregando espacio en blanco a las cadenas para que tengan la misma longitud antes de compararlas. Esto explica los fenómenos que estamos viendo.
no hace esto con el operador LIKE, sin embargo, lo que explica la diferencia en el comportamiento.
comparaciones cuando los espacios adicionales importan
digamos que queremos hacer una comparación donde la diferencia en los espacios finales importa.
una opción es usar el operador LIKE Como vimos algunos ejemplos atrás., Sin embargo, este no es el uso típico del operador LIKE, así que asegúrese de comentar y explicar lo que su consulta está tratando de hacer al usarlo. Lo último que desea es que algún futuro mantenedor de su código lo cambie de nuevo a un signo igual porque no ven ningún carácter comodín.
Otra opción que he visto es realizar una DATALENGTH comparación además del valor de comparación:

Esta solución no es adecuada para todos los escenarios sin embargo., Para empezar, no tiene forma de saber si SQL Server ejecutará primero su comparación de valor o predicado de longitud de datos. Esto podría causar estragos en el uso del índice y causar un bajo rendimiento.
un problema más grave puede ocurrir si está comparando campos con diferentes tipos de datos., Por ejemplo, al comparar un tipo de datos VARCHAR con NVARCHAR, es bastante fácil crear un escenario en el que su consulta de comparación utilizando DATALENGTH activará un falso positivo:

Aquí el NVARCHAR almacena 2 bytes para cada carácter, haciendo que las longitudes de datos de un solo carácter NVARCHAR sean iguales a un carácter + un valor varchar de espacio.
lo mejor que puede hacer en estos escenarios es comprender sus datos y elegir una solución que funcione para su situación particular.,
y tal vez recortar sus datos antes de la inserción (si tiene sentido hacerlo)!















