K-vecinos más cercanos: ¿quiénes están cerca de ti?
si vas a la universidad, probablemente hayas participado en al menos un par de organizaciones estudiantiles. Estoy comenzando mi 1er semestre como estudiante de posgrado en Rochester Tech, y hay más de 350 organizaciones aquí. Se clasifican en diferentes categorías en función de los intereses del estudiante. ¿Qué define estas categorías y quién dice qué organización entra en qué categoría? Estoy seguro de que si le preguntaras a las personas que dirigen estas organizaciones, no dirían que su organización es igual a la de otra persona, pero de alguna manera sabes que son similares., Fraternidades y hermandades tienen el mismo interés en la vida griega. El fútbol intramuros y el tenis de club tienen el mismo interés en los deportes. El grupo Latino y el Grupo Asiático-Americano tienen el mismo interés en la diversidad cultural. Tal vez si midiera los eventos y reuniones organizados por estas organizaciones, podría averiguar automáticamente a qué categoría pertenece una organización. Usaré organizaciones estudiantiles para explicar algunos de los conceptos de K-nearest Neighbors, posiblemente el algoritmo de aprendizaje automático más simple que existe. La construcción del modelo consiste solo en almacenar el conjunto de datos de entrenamiento., Para hacer una predicción para un nuevo punto de datos, el algoritmo encuentra los puntos de datos más cercanos en el conjunto de datos de entrenamiento: sus «vecinos más cercanos».»
cómo funciona
en su versión más simple, el algoritmo k-NN solo considera exactamente un vecino más cercano, que es el punto de datos de entrenamiento más cercano al punto para el que queremos hacer una predicción. La predicción es entonces simplemente la salida conocida para este punto de entrenamiento., La figura siguiente ilustra esto para el caso de la clasificación en la forja del conjunto de datos:

Aquí, hemos añadido tres nuevos puntos de datos, se muestra como las estrellas. Para cada uno de ellos, marcamos el punto más cercano en el conjunto de entrenamiento. La predicción del algoritmo de un vecino más cercano es la etiqueta de ese punto (mostrada por el color de la Cruz).
en lugar de considerar solo el vecino más cercano, también podemos considerar un número arbitrario, k, de vecinos., Aquí es de donde viene el nombre del algoritmo k-nearest neighbors. Cuando consideramos más de un vecino, usamos la votación para asignar una etiqueta. Esto significa que para cada punto de prueba, contamos cuántos vecinos pertenecen a la clase 0 y cuántos vecinos pertenecen a la clase 1. Luego asignamos la clase que es más frecuente: En otras palabras, la clase mayoritaria entre los vecinos k-más cercanos., El ejemplo siguiente utiliza los cinco vecinos más cercanos:
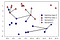
de Nuevo, la predicción se muestra como el color de la cruz. Puede ver que la predicción para el nuevo punto de datos en la parte superior izquierda no es la misma que la predicción cuando usamos solo un vecino.
mientras que esta ilustración es para un problema de clasificación binaria, este método se puede aplicar a conjuntos de datos con cualquier número de clases., Para más clases, contamos cuántos vecinos pertenecen a cada clase y nuevamente predecimos la clase más común.,facilitar orden
el código Python para la función está aquí:
vamos a profundizar un poco más en el código:
- La función knnclassify toma 4 entradas: el vector de entrada para clasificar llamado a, una matriz completa de ejemplos de entrenamiento llamado dataset, un vector de etiquetas llamado labels, y K — el número de vecinos más cercanos para usar en la votación., El vector labels debe tener tantos elementos como filas en la matriz del conjunto de datos.
- calculamos las distancias entre a y el punto actual utilizando la distancia Euclidiana.
- Luego ordenamos las distancias en un orden creciente.
- a continuación, las distancias K más bajas se utilizan para votar en la clase de A.
- después de eso, tomamos el diccionario classCount y lo descomponemos en una lista de tuplas y luego ordenamos las tuplas por el segundo elemento de la tupla. La ordenación se realiza al revés, por lo que tenemos de mayor a menor.,
- Por último, devolvemos la etiqueta del elemento que aparece con más frecuencia.
implementación a través de Scikit-Learn
ahora echemos un vistazo a cómo podemos implementar el algoritmo kNN utilizando scikit-learn:
echemos un vistazo al código:
- Primero, generamos el conjunto de datos Iris.
- luego, dividimos nuestros datos en un conjunto de entrenamiento y prueba para evaluar el rendimiento de la generalización.
- a continuación, especificamos el número de vecinos (k) a 5.
- a continuación, ajustamos el clasificador utilizando el conjunto de entrenamiento.,
- Para hacer predicciones sobre los datos de la prueba, llamamos al método predict. Para cada punto de datos en el conjunto de prueba, el método calcula sus vecinos más cercanos en el conjunto de entrenamiento y encuentra la clase más común entre ellos.
- Por último, evaluamos qué tan bien se generaliza nuestro modelo llamando al método de puntuación con datos de prueba y etiquetas de prueba.
ejecutar el modelo debería darnos una precisión del conjunto de pruebas del 97%, lo que significa que el modelo predijo la clase correctamente para el 97% de las muestras en el conjunto de datos de prueba.,

Fortalezas y Debilidades
En principio, hay dos parámetros importantes para la KNeighbors clasificador: el número de vecinos y la forma de medir la distancia entre puntos de datos.
- en la práctica, usar un pequeño número de vecinos como tres o cinco a menudo funciona bien, pero sin duda debe ajustar este parámetro.
- Elegir la medida de distancia correcta es algo complicado., De forma predeterminada, se utiliza la distancia euclidiana, que funciona bien en muchos ajustes.
una de las fortalezas de k-NN es que el modelo es muy fácil de entender, y a menudo da un rendimiento razonable sin muchos ajustes. El uso de este algoritmo es un buen método de referencia para probar antes de considerar técnicas más avanzadas. Construir el modelo de vecinos más cercano suele ser muy rápido, pero cuando su conjunto de entrenamiento es muy grande (ya sea en número de características o en número de muestras) la predicción puede ser lenta. Cuando se utiliza el algoritmo k-NN, es importante preprocesar los datos., Este enfoque a menudo no funciona bien en conjuntos de datos con muchas entidades (cientos o más), y lo hace particularmente mal con conjuntos de datos donde la mayoría de las entidades son 0 la mayor parte del tiempo (los llamados conjuntos de datos dispersos).
En conclusión
el algoritmo k-nearest Neighbors es una forma simple y efectiva de clasificar los datos. Es un ejemplo de aprendizaje basado en instancias, donde necesita tener instancias de datos a mano para realizar el algoritmo de aprendizaje automático. El algoritmo tiene que transportar el conjunto de datos completo; para conjuntos de datos grandes, esto implica una gran cantidad de almacenamiento., Además, debe calcular la medición de distancia para cada pieza de datos en la base de datos, y esto puede ser engorroso. Un inconveniente adicional es que kNN no le da ninguna idea de la estructura subyacente de los datos; no tiene idea de cómo se ve una instancia «promedio» o «ejemplar» de cada clase.
por lo tanto, mientras que el algoritmo k-neighbors más cercano es fácil de entender, no se usa a menudo en la práctica, debido a que la predicción es lenta y su incapacidad para manejar muchas características.,
fuentes de referencia:
- Aprendizaje automático en acción por Peter Harrington (2012)
- Introducción al aprendizaje automático con Python por Sarah Guido y Andreas Muller (2016)















