k-lähimmät naapurit: ketkä ovat lähelläsi?
Jos lähdet opiskelemaan, olet todennäköisesti osallistunut ainakin pariin opiskelijajärjestöön. Aloitan 1. lukukauteni jatko-opiskelijana Rochester Techissä, ja täällä on yli 350 organisaatiota. Ne lajitellaan eri luokkiin opiskelijan kiinnostuksen perusteella. Mikä määrittelee nämä kategoriat, ja kuka sanoo, mikä örkki menee mihin kategoriaan? Olen varma, että jos olet pyytänyt ihmisiä käynnissä näiden järjestöjen, he eivät sanovat, että heidän org on aivan kuin joku muu org, mutta jollain tavalla he ovat samanlaisia., Veljeskunnilla ja sororitiikoilla on sama kiinnostus kreikkalaiseen elämään. Intramural soccer ja club tennis ovat yhtä kiinnostuneita urheilusta. Latinoryhmällä ja Aasialaisamerikkalaisella ryhmällä on sama kiinnostus kulttuuriseen monimuotoisuuteen. Ehkä jos mittaisit näiden orgien tapahtumia ja kokouksia, voisit automaattisesti selvittää, mihin luokkaan organisaatio kuuluu. Käytän opiskelijajärjestöjä selittämään joitakin K-lähimpien naapureiden käsitteitä, luultavasti yksinkertaisin koneoppimisen algoritmi siellä. Mallin rakentaminen koostuu vain koulutustietojen säilyttämisestä., Tehdäkseen ennusteen uudesta datapisteestä algoritmi löytää koulutustietojen lähimmät datapisteet-sen ” lähimmät naapurit.”
Miten Se Toimii
se yksinkertaisin versio, k-NN-algoritmi vain katsoo tarkasti, lähin naapuri, joka on lähinnä koulutusta koskevat tiedot viittaavat siihen pisteeseen, että haluamme tehdä ennuste. Ennuste on sitten yksinkertaisesti tunnettu tuotos tästä harjoituspisteestä., Kuva alla havainnollistaa tässä tapauksessa luokittelun forge aineisto:

Tässä, olemme lisänneet kolme uutta tietoja pistettä, näkyy tähtiä. Jokaiselle niistä merkitsimme lähimmän kohdan harjoitussarjassa. Yhden lähimmän naapurin algoritmin ennustaminen on kyseisen pisteen merkki (joka näkyy ristin värillä).
sen sijaan, että harkitsisimme vain lähintä naapuria, voidaan harkita myös naapureiden mielivaltaista lukua, K: ta., Tästä k-lähinaapurin algoritmin nimi tulee. Kun harkitsemme useampaa kuin yhtä naapuria, käytämme äänestystä nimilapun määrittämiseen. Tämä tarkoittaa sitä, että jokaisesta testipisteestä lasketaan, kuinka monta naapuria kuuluu luokkaan 0 ja kuinka monta naapuria kuuluu luokkaan 1. Sitten määritämme luokan, joka on yleisempi: toisin sanoen enemmistöluokan k-lähimpien naapureiden joukossa., Seuraavassa esimerkissä käytetään viisi lähimmät naapurit:
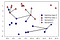
Jälleen ennustaminen on osoittanut väri rajat. Voit nähdä, että ennuste uuden datapisteen yläosassa vasemmalla ei ole sama kuin ennuste, kun käytimme vain yksi naapuri.
vaikka tämä kuvaus koskee binääriluokitusongelmaa, tätä menetelmää voidaan soveltaa mihin tahansa luokkaan kuuluviin tietokokonaisuuksiin., Useammalle luokalle lasketaan, kuinka monta naapuria kuuluu kuhunkin luokkaan ja ennustetaan taas yleisintä luokkaa.,keventäminen, jotta
Python-koodi toiminto on tässä:
katsotaanpa kaivaa hieman syvemmälle-koodi:
- toiminto knnclassify kestää 4-sisääntulot: input vektori luokitella kutsutaan, koko matriisi koulutus esimerkkejä nimeltään aineisto, vektori tarroja kutsutaan tarrat, ja k — määrä naapurit käyttää äänestykseen., Tarrojen vektorilla pitäisi olla siinä yhtä monta elementtiä kuin dataSet-matriisissa on rivejä.
- lasketaan A: n ja nykyisen pisteen väliset etäisyydet euklidisen etäisyyden avulla.
- sitten lajittelemme etäisyydet yhä suuremmassa järjestyksessä.
- Seuraava, alin k etäisyydet ovat tottuneet äänestämään luokka A.
- sen Jälkeen otamme classCount sanakirja ja hajoavat sen luettelo tuplat ja sitten lajitella tuplat 2nd kohteen monikko. Sort tehdään päinvastoin, joten meillä on suurin ja pienin.,
- lopuksi palautamme yleisimmin esiintyvän tuotteen etiketin.
Täytäntöönpanon Kautta Scikit-Learn
Nyt, katsotaanpa katsomaan miten voimme toteuttaa kNN-algoritmi käyttää scikit-learn:
katsotaanpa koodi:
- Ensimmäinen, me tuottaa iris-aineisto.
- sitten jaoimme tietomme koulutus-ja testisarjaksi, jolla arvioidaan yleistystehoa.
- seuraavaksi tarkennamme naapureiden (k) määrän 5: een.
- seuraavaksi sovimme luokittajan harjoittelusarjaa käyttäen.,
- tehdäksemme ennusteita testitiedoista kutsumme ennustusmenetelmää. Kunkin tiedot kohta testi asettaa, menetelmä laskee sen lähimmät naapurit koulutusta asetettu ja löytää yleisimpiä luokan joukossa.
- lopuksi arvioimme, kuinka hyvin mallimme yleistyy kutsumalla pisteytysmenetelmää testitiedoilla ja testimerkinnöillä.
Käynnissä malli olisi antaa meille testin tarkkuus 97%, eli malli ennusti luokan oikein 97% näytteet testi-aineisto.,

Vahvuudet ja Heikkoudet
Periaatteessa, on kaksi tärkeää parametria, KNeighbors luokittelija: määrä naapureita ja miten voit mitata etäisyys tietoja pistettä.
- käytännössä pienellä määrällä naapureita, kuten kolme tai viisi, toimii usein hyvin, mutta tätä parametria kannattaa varmasti säätää.
- oikean etäisyysmittarin valitseminen on hieman hankalaa., Oletuksena käytetään Euklidista etäisyyttä, joka toimii hyvin monissa asetuksissa.
Yksi vahvuuksista k-NN on, että malli on erittäin helppo ymmärtää, ja usein antaa kohtuullinen suorituskyky ilman paljon muutoksia. Tämän algoritmin käyttäminen on hyvä perustason menetelmä kokeilla ennen kuin harkitaan kehittyneempiä tekniikoita. Rakennus naapurit malli on yleensä hyvin nopeasti, mutta kun teidän koulutus asetettu on erittäin suuri (joko useita ominaisuuksia tai näytteiden lukumäärä) ennustaminen voi olla hidasta. K-NN-algoritmia käytettäessä on tärkeää esikäsitellä tietosi., Tämä lähestymistapa ei useinkaan tehdä hyvin datajoukkojen monia ominaisuuksia (satoja tai enemmän), ja se ei erityisen huonosti aineistot, jossa useimmat ominaisuudet ovat 0 suurimman osan ajasta (ns. harva aineistot).
lopuksi
k-Naapurit-algoritmi on yksinkertainen ja tehokas tapa luokitella dataa. Se on esimerkki siitä, instance-based learning, jossa sinun täytyy olla tapauksia tiedot käden suorittaa kone-oppimisen algoritmi. Algoritmin on kuljettava koko tietokokonaisuuden ympäri; suurille tietokokonaisuuksille tämä merkitsee suurta tallennusmäärää., Lisäksi, sinun täytyy laskea etäisyyden mittaus jokainen pala tiedot tietokantaan, ja tämä voi olla hankalaa. Ylimääräinen haittapuoli on, että kNN ei anna sinulle mitään ajatusta taustalla rakenne tiedot, sinulla ei ole aavistustakaan, mitä ”keskimääräinen” tai ”esikuva” esimerkiksi kunkin luokan näyttää.
Joten, kun lähin k-naapurit-algoritmi on helppo ymmärtää, se ei ole usein käytetty käytännössä, koska ennustaminen on hidas ja sen kyvyttömyys käsitellä monia ominaisuuksia.,
Viite Lähteet:
- koneoppimisen toiminnassa Peter Harrington (2012)
- Introduction to Machine Learning Python Sarah Guido ja Andreas Muller (2016)















