Záró szóközök az SQL Serverben
nézze meg az e heti videót a YouTube-on
régen építettem egy alkalmazást, amely rögzítette a felhasználói bemenetet. Az alkalmazás egyik jellemzője az volt, hogy összehasonlítsa a felhasználó bemenetét egy értékadatbázissal.
az alkalmazás ezt a szövegösszehasonlítást egy SQL Server tárolt eljárás részeként hajtotta végre, lehetővé téve számomra, hogy szükség esetén könnyen frissítsem az üzleti logikát a jövőben.
egy nap kaptam egy e-mailt egy felhasználótól, mondván, hogy az általuk begépelt érték megegyezik egy olyan adatbázis-értékkel, amelyről tudták, hogy nem felel meg., Ez az a nap, amikor felfedeztem az SQL Server ellen intuitív egyenlőségi összehasonlítását, amikor a tér karakterekkel foglalkoztam.
Párnázott fehér tér
valószínűleg tudatában van annak, hogy a CHAR adattípus a megadott hossz eléréséig szóközökkel párolja az értéket:
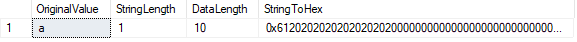
a LEN() függvény a karakterláncunkban lévő karakterek számát mutatja, míg a DATALENGTH() függvény az adott karakterlánc által használt bájtok számát mutatja.
ebben az esetben a DATALENGTH egyenlő 10., Ez az eredmény annak köszönhető, hogy a párnázott terek után előforduló karakter ” a ” annak érdekében, hogy töltse ki a meghatározott CHAR hossza 10. Ezt megerősíthetjük úgy, hogy az értéket hexadecimálisra konvertáljuk. Látjuk a 61 értéket (“a” hexában), amelyet kilenc ” 20 ” érték (szóköz) követ.
Ha meg szeretnénk változtatni a változó adatok típus VARCHAR, majd meglátjuk, hogy az érték már nincs párnázott terek:

Tekintettel arra, hogy egy adattípust párna értékek a szóköz karaktert, míg a másik nem, mi történik, ha összehasonlítjuk a kettőt?,
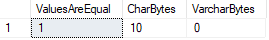
ebben az esetben az SQL Server mindkét értéket egyenlőnek tekinti, annak ellenére, hogy megerősíthetjük, hogy a DATALENGTHs más.
Ez a viselkedés azonban nem csak vegyes adattípus-összehasonlításoknál fordul elő. Ha összehasonlítjuk az azonos adattípusú két értéket, egy értékkel, amely több szóköz karaktert tartalmaz, tapasztalunk valamit…váratlan:

annak ellenére, hogy két változónk különböző értékekkel rendelkezik (üres a négy szóköz karakterhez képest), az SQL Server ezeket az értékeket egyenlőnek tekinti.,
ha hozzáadunk egy karaktert néhány záró szóközzel, ugyanazt a viselkedést fogjuk látni:

mindkét érték egyértelműen eltérő, de az SQL Server egyenlőnek tartja őket egymással. Váltás az egyenlő jel egy hasonló operátor megváltoztatja a dolgokat kissé:

annak ellenére, hogy azt hiszem, hogy egy hasonló nélkül helyettesítő karakter viselkedne, mint egy egyenlő jel, SQL Server nem hajtja végre ezeket az összehasonlításokat ugyanúgy.,
Ha cserélünk vissza, hogy az egyenlőségjel összehasonlítás, valamint előtag a karakter érték terek mi is észre fogod venni, hogy más lesz az eredmény:

SQL Server úgy véli, a két érték egyenlő-függetlenül attól, terek előforduló, a végén egy string. Szóköz megelőző karakterlánc azonban, már nem tekinthető a mérkőzés.
mi folyik itt?
ANSI
míg a számláló intuitív, az SQL Server funkcionalitása indokolt., Az SQL Server követi az ANSI specifikációt a karakterláncok összehasonlításához, fehér tér hozzáadásával a karakterláncokhoz úgy, hogy azok azonos hosszúak legyenek, mielőtt összehasonlítanák őket. Ez magyarázza a jelenségeket, amelyeket látunk.
ezt a hasonló operátorral nem teszi meg, ami magyarázza a viselkedés különbségét.
összehasonlítások, ha az extra terek számítanak
tegyük fel, hogy összehasonlítást akarunk végezni, ahol a hátsó terek különbsége számít.
az egyik lehetőség a hasonló operátor használata, mivel néhány példát láttunk vissza., Ez azonban nem a hasonló operátor tipikus használata, ezért ügyeljen arra, hogy kommentálja, majd elmagyarázza, mit próbál tenni a lekérdezés használatával. Az utolsó dolog, amit szeretne, a kód jövőbeli karbantartója, hogy visszaállítsa azt egyenlő jelre, mert nem látnak semmilyen wild card karaktert.
egy másik lehetőség, hogy láttam, hogy végre egy DATALENGTH összehasonlítás mellett az érték összehasonlítás:

Ez a megoldás nem megfelelő minden forgatókönyv azonban., Kezdetnek, akkor nem lehet tudni, ha az SQL Server végrehajtja az érték összehasonlítása vagy DATALENGTH predikátum első. Ez tönkreteheti az indexhasználatot, és rossz teljesítményt okozhat.
súlyosabb probléma fordulhat elő, ha a mezőket különböző adattípusokkal hasonlítja össze., Például, ha összehasonlítjuk a VARCHAR Nvarchar adattípus, ez elég könnyű létrehozni egy forgatókönyvet, ahol az összehasonlító lekérdezés segítségével DATALENGTH indít hamis pozitív:

itt az NVARCHAR tárolja 2 bájt minden karakter, ami a DATALENGTHs egyetlen karakter NVARCHAR egyenlő egy karakter + egy hely VARCHAR értéket.
a legjobb dolog, hogy ezekben a forgatókönyvekben megérteni az adatokat, majd válasszon egy megoldást, hogy működni fog az adott helyzetben.,
és talán vágja le az adatokat a beillesztés előtt (ha van értelme ezt megtenni)!















