k-Vicini più vicini: chi ti è vicino?
Se vai al college, probabilmente hai partecipato ad almeno un paio di organizzazioni studentesche. Sto iniziando il mio 1 ° semestre come studente laureato a Rochester Tech, e ci sono più di 350 organizzazioni qui. Sono ordinati in diverse categorie in base agli interessi dello studente. Cosa definisce queste categorie e chi dice quale organizzazione rientra in quale categoria? Sono sicuro che se hai chiesto alle persone che gestiscono queste organizzazioni, non direbbero che la loro organizzazione è proprio come l’organizzazione di qualcun altro, ma in qualche modo sai che sono simili., Fraternità e sororities hanno lo stesso interesse per la vita greca. Calcio intramurale e tennis club hanno lo stesso interesse per lo sport. Il gruppo latino e il gruppo asiatico americano hanno lo stesso interesse per la diversità culturale. Forse se hai misurato gli eventi e le riunioni gestite da queste organizzazioni, potresti capire automaticamente a quale categoria appartiene un’organizzazione. Userò le organizzazioni studentesche per spiegare alcuni dei concetti di k-Nearest Neighbors, probabilmente il più semplice algoritmo di apprendimento automatico là fuori. La creazione del modello consiste solo nella memorizzazione del set di dati di allenamento., Per fare una previsione per un nuovo punto dati, l’algoritmo trova i punti dati più vicini nel set di dati di formazione — i suoi “vicini più vicini.”
Come funziona
Nella sua versione più semplice, l’algoritmo k-NN considera solo esattamente un vicino più vicino, che è il punto di dati di allenamento più vicino al punto per cui vogliamo fare una previsione. La previsione è quindi semplicemente l’output noto per questo punto di allenamento., La figura seguente illustra questo il caso di classificazione sulla fucina set di dati:

Qui abbiamo aggiunto tre nuovi punti di dati, come mostrato di stelle. Per ognuno di essi, abbiamo segnato il punto più vicino nel set di allenamento. La previsione dell’algoritmo one-nearest-neighbor è l’etichetta di quel punto (mostrata dal colore della croce).
Invece di considerare solo il vicino più vicino, possiamo anche considerare un numero arbitrario, k, di vicini., Questo è dove il nome del k-nearest neighbors algoritmo viene da. Quando si considera più di un vicino, usiamo il voto per assegnare un’etichetta. Ciò significa che per ogni punto di prova, contiamo quanti vicini appartengono alla classe 0 e quanti vicini appartengono alla classe 1. Assegniamo quindi la classe che è più frequente: in altre parole, la classe di maggioranza tra i k-vicini più vicini., L’esempio seguente utilizza le cinque più vicini:
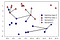
di Nuovo, la previsione è mostrato come il colore della croce. Puoi vedere che la previsione per il nuovo punto dati in alto a sinistra non è la stessa della previsione quando abbiamo usato solo un vicino.
Mentre questa illustrazione riguarda un problema di classificazione binaria, questo metodo può essere applicato a set di dati con qualsiasi numero di classi., Per più classi, contiamo quanti vicini appartengono a ciascuna classe e di nuovo prediciamo la classe più comune.,andamento ordine
Il codice Python per la funzione è qui:
Cerchiamo di scavare un po ‘ più in profondità il codice:
- La funzione knnclassify prende 4 ingressi: il vettore d’ingresso per classificare chiamato, una matrice completa di formazione esempi chiamato set di dati, un vettore di etichette chiamato etichette, e k è il numero di vicini per utilizzare al voto., Il vettore etichette dovrebbe avere tanti elementi in esso quante sono le righe nella matrice del set di dati.
- Calcoliamo le distanze tra A e il punto corrente usando la distanza euclidea.
- Quindi ordiniamo le distanze in ordine crescente.
- Successivamente, le distanze k più basse vengono utilizzate per votare la classe di A.
- Dopo di che, prendiamo il dizionario classCount e lo scomponiamo in un elenco di tuple e quindi ordiniamo le tuple per il 2 ° elemento nella tupla. L’ordinamento è fatto al contrario, quindi abbiamo il più grande al più piccolo.,
- Infine, restituiamo l’etichetta dell’articolo che si verifica più frequentemente.
l’Implementazione Via Scikit-Imparare
Ora, diamo un’occhiata a come possiamo implementare l’algoritmo kNN utilizzando scikit-imparare:
vediamo il codice:
- in Primo luogo, siamo in grado di generare l’iride set di dati.
- Quindi, abbiamo diviso i nostri dati in un set di allenamento e test per valutare le prestazioni di generalizzazione.
- Successivamente, specifichiamo il numero di vicini (k) a 5.
- Successivamente, adattiamo il classificatore usando il set di allenamento.,
- Per fare previsioni sui dati del test, chiamiamo il metodo predict. Per ogni punto dati nel set di test, il metodo calcola i suoi vicini più vicini nel set di allenamento e trova la classe più comune tra di loro.
- Infine, valutiamo quanto bene il nostro modello generalizza chiamando il metodo score con dati di test e etichette di test.
L’esecuzione del modello dovrebbe darci una precisione del set di test del 97%, il che significa che il modello ha previsto correttamente la classe per il 97% dei campioni nel set di dati di test.,

punti di Forza e di Debolezza
In linea di principio, ci sono due parametri importanti per la KNeighbors di classificazione: il numero di vicini di casa e come si misura la distanza tra i punti di dati.
- In pratica, usare un piccolo numero di vicini come tre o cinque spesso funziona bene, ma dovresti certamente regolare questo parametro.
- Scegliere la giusta misura di distanza è un po ‘ complicato., Per impostazione predefinita, viene utilizzata la distanza euclidea, che funziona bene in molte impostazioni.
Uno dei punti di forza di k-NN è che il modello è molto facile da capire e spesso offre prestazioni ragionevoli senza molte regolazioni. L’utilizzo di questo algoritmo è un buon metodo di base da provare prima di considerare tecniche più avanzate. Costruire il modello neighbors più vicino è di solito molto veloce, ma quando il set di allenamento è molto grande (in numero di funzionalità o in numero di campioni) la previsione può essere lenta. Quando si utilizza l’algoritmo k-NN, è importante pre-elaborare i dati., Questo approccio spesso non funziona bene su set di dati con molte funzionalità (centinaia o più), e lo fa particolarmente male con set di dati in cui la maggior parte delle funzionalità sono 0 la maggior parte del tempo (i cosiddetti set di dati sparsi).
In conclusione
L’algoritmo k-Nearest Neighbors è un modo semplice ed efficace per classificare i dati. È un esempio di apprendimento basato su istanze, in cui è necessario avere istanze di dati a portata di mano per eseguire l’algoritmo di apprendimento automatico. L’algoritmo deve portare in giro il set di dati completo; per i set di dati di grandi dimensioni, ciò implica una grande quantità di spazio di archiviazione., Inoltre, è necessario calcolare la misurazione della distanza per ogni pezzo di dati nel database, e questo può essere ingombrante. Un ulteriore inconveniente è che kNN non ti dà alcuna idea della struttura sottostante dei dati; non hai idea di come sia un’istanza “media” o “esemplare” di ogni classe.
Quindi, mentre l’algoritmo k-neighbors più vicino è facile da capire, non è spesso usato nella pratica, a causa della lentezza della previsione e della sua incapacità di gestire molte funzionalità.,
Fonti di riferimento:
- Machine Learning In Action di Peter Harrington (2012)
- Introduzione all’apprendimento automatico con Python di Sarah Guido e Andreas Muller (2016)















