Spazi finali in SQL Server
Guarda il video di questa settimana su YouTube
Molto tempo fa ho creato un’applicazione che ha catturato l’input dell’utente. Una caratteristica dell’applicazione era quella di confrontare l’input dell’utente con un database di valori.
L’app ha eseguito questo confronto di testo come parte di una stored procedure SQL Server, permettendomi di aggiornare facilmente la logica di business in futuro, se necessario.
Un giorno, ho ricevuto un’e-mail da un utente che diceva che il valore che stavano digitando corrispondeva a un valore di database che sapevano non doveva corrispondere., Questo è il giorno in cui ho scoperto il confronto di uguaglianza intuitivo di SQL Server quando si tratta di caratteri di spazio finali.
collare Imbottito spazio bianco
Si sono probabilmente consapevoli del fatto che il tipo di dati CHAR pastiglie il valore con spazi fino a raggiungere la lunghezza definita è raggiunto:
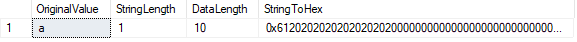
La funzione LEN() indica il numero di caratteri nella nostra stringa, mentre il DATALENGTH funzione() ci mostra il numero di bytes della stringa.
In questo caso, DATALENGTH è uguale a 10., Questo risultato è dovuto agli spazi imbottiti che si verificano dopo il carattere ” a ” per riempire la lunghezza del carattere definita di 10. Possiamo confermarlo convertendo il valore in esadecimale. Vediamo il valore 61 (“a “in esadecimale) seguito da nove valori” 20 ” (spazi).
Se cambiamo il tipo di dati della nostra variabile in VARCHAR, vedremo che il valore non è più riempito di spazi:

Dato che uno di questi tipi di dati riempie i valori con caratteri di spazio mentre l’altro no, cosa succede se confrontiamo i due?,
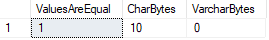
In questo caso SQL Server considera entrambi i valori uguali, anche se possiamo confermare che le lunghezze dei dati sono diverse.
Questo comportamento non si verifica solo con confronti di tipi di dati misti. Se confrontiamo due valori dello stesso tipo di dati, con un valore contenente diversi caratteri di spazio, sperimentiamo qualcosa…inaspettato:

Anche se le nostre due variabili hanno valori diversi (uno spazio vuoto rispetto a quattro caratteri di spazio), SQL Server considera questi valori uguali.,
Se aggiungiamo un carattere con alcuni spazi bianchi finali vedremo lo stesso comportamento:

Entrambi i valori sono chiaramente diversi, ma SQL Server li considera uguali tra loro. Passare il nostro segno di uguale a un operatore SIMILE cambia leggermente le cose:

Anche se penserei che un LIKE senza caratteri jolly si comporterebbe proprio come un segno di uguale, SQL Server non esegue questi confronti allo stesso modo.,
Se torniamo al nostro confronto di segno di uguale e prefiggiamo il nostro valore di carattere con spazi noteremo anche un risultato diverso:

SQL Server considera due valori uguali indipendentemente dagli spazi che si verificano alla fine di una stringa. Gli spazi che precedono una stringa, tuttavia, non sono più considerati una corrispondenza.
Cosa sta succedendo?
ANSI
Mentre contro intuitivo, la funzionalità di SQL Server è giustificata., SQL Server segue la specifica ANSI per il confronto delle stringhe, aggiungendo spazio bianco alle stringhe in modo che abbiano la stessa lunghezza prima di confrontarle. Questo spiega i fenomeni che stiamo vedendo.
Tuttavia non lo fa con l’operatore LIKE, il che spiega la differenza di comportamento.
Confronti quando gli spazi extra contano
Diciamo che vogliamo fare un confronto in cui la differenza negli spazi finali è importante.
Un’opzione è quella di utilizzare l’operatore LIKE come abbiamo visto alcuni esempi indietro., Tuttavia, questo non è l’uso tipico dell’operatore LIKE, quindi assicurati di commentare e spiegare cosa sta tentando di fare la tua query usandola. L’ultima cosa che vuoi è che un futuro manutentore del tuo codice lo riporti a un segno di uguale perché non vede alcun carattere jolly.
Un’altra opzione che ho visto è quella di eseguire un confronto DATALENGTH oltre al confronto dei valori:

Tuttavia questa soluzione non è adatta per ogni scenario., Per cominciare, non si ha modo di sapere se SQL Server eseguirà prima il confronto dei valori o il predicato DATALENGTH. Ciò potrebbe distruggere il caos sull’utilizzo dell’indice e causare prestazioni scadenti.
Si può verificare un problema più serio se si confrontano campi con tipi di dati diversi., Ad esempio, quando si confronta un tipo di dati VARCHAR con NVARCHAR, è abbastanza facile creare uno scenario in cui la query di confronto utilizzando DATALENGTH attiverà un falso positivo:

Qui NVARCHAR memorizza 2 byte per ogni carattere, causando la lunghezza dei dati di un singolo carattere NVARCHAR uguale a un carattere + un valore VARCHAR dello spazio.
La cosa migliore da fare in questi scenari è capire i tuoi dati e scegliere una soluzione che funzioni per la tua situazione particolare.,
E magari taglia i tuoi dati prima dell’inserimento (se ha senso farlo)!















