k-最近隣:あなたの近くにいるのは誰ですか?
あなたが大学に行くなら、あなたはおそらく少なくともいくつかの学生組織に参加しています。 私はロチェスター工科大学の大学院生として私の1学期を始めています、そしてここには350以上の組織があります。 彼らは学生の興味に基づいて異なるカテゴリにソートされます。 何が定義され、愛するorgがどうなのです。 あなたがこれらの組織を運営している人々に尋ねた場合、彼らは彼らの組織が他の誰かの組織と同じであるとは言わないでしょうが、何らかの形で, 友愛とソロリティは、ギリシャの生活の中で同じ関心を持っています。 学内サッカー、テニスクラブと同じ利です。 のラティーノグループのアジア系アメリカグループの利益に文化の多様性. おそらく、これらの組織によって実行されるイベントや会議を測定した場合、組織が属するカテゴリを自動的に把握することができます。 学生組織を使用して、おそらく最も単純な機械学習アルゴリズムであるk-Nearest Neighborsの概念のいくつかを説明します。 建物モデルだけで構成されて保存の研修データを得る。, 新しいデータ点の予測を行うために、アルゴリズムは学習データセット内の最も近いデータ点、つまりその”最近傍”を検索します。”
どのように動作するか
最も単純なバージョンでは、k-NNアルゴリズムは、予測を行いたい点に最も近いトレーニングデータ点である、正確に一つの最 予測は、このトレーニングポイントの既知の出力になります。, 以下の図は、forgeデータセットの分類の場合にこれを示しています。

ここでは、星として表示される新しいデータポイント。 それぞれについて、トレーニングセットの最も近い点をマークしました。 One-nearest-neighborアルゴリズムの予測は、その点のラベル(十字の色で示されています)です。
最も近い近傍のみを考慮する代わりに、任意の数kの近傍を考慮することもできます。, これは、k最近傍アルゴリズムの名前が由来する場所です。 複数のネイバーを検討する場合は、投票を使用してラベルを割り当てます。 これは、各テストポイントについて、クラス0に属する近傍の数とクラス1に属する近傍の数を数えることを意味します。 次に、より頻繁なクラスを割り当てます:言い換えれば、k最近傍の中の大多数のクラスを割り当てます。,
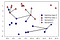
ここでも、予測は、予測の色として表示されます。クロス 左上の新しいデータポイントの予測は、一つのネイバーだけを使用した場合の予測と同じではないことがわかります。
この図はバイナリ分類問題のためのものですが、この方法は任意の数のクラスを持つデータセットに適用できます。, より多くのクラスについては、各クラスに属する隣人の数を数え、再び最も一般的なクラスを予測します。,この関数のPythonコードは次のとおりです。
コードをもう少し深く掘り下げてみましょう。
- 関数knnclassifyは、aと呼ばれる分類する入力ベクトル、datasetと呼ばれるトレーニング例の完全な行列、labelsと呼ばれるラベルのベクトル、およびk—投票で使用する最近傍の数の4つの入力を受け取ります。, Labelsベクトルには、データセット行列の行と同じ数の要素が含まれている必要があります。
- ユークリッド距離を使用して、aと現在の点との間の距離を計算します。
- 次に、距離を増やした順に並べ替えます。その後、classCount辞書を取り、それをタプルのリストに分解し、タプルの2番目の項目でタプルをソートします。 並べ替えは逆に行われるので、最大から最小になります。,
- 最後に、最も頻繁に発生するアイテムのラベルを返します。
Scikit-Learnによる実装
次に、scikit-learnを使用してkNNアルゴリズムを実装する方法を見てみましょう。
コードを見てみましょう。
- まず、irisを生成します。データセット。
- 次に、データをトレーニングセットとテストセットに分割して、一般化のパフォーマンスを評価します。
- 次に、隣人の数(k)を5に指定します。
- 次に、トレーニングセットを使用して分類器を近似します。,
- テストデータの予測を行うために、predictメソッドを呼び出します。 このメソッドは、テストセット内の各データ点について、トレーニングセット内の最近傍を計算し、その中で最も一般的なクラスを検索します。
- 今後の評価方を広く募集するとともに、モデルgeneralizesを呼び出しの方法と試験のデータを試験する。
モデルを実行すると、テストセットの精度は97%になり、モデルはテストデータセット内のサンプルの97%についてクラスを正しく予測しました。,

長所と短所
原則として、knighbors分類器の二つの重要なパラメータ:近傍の数とデータポイント間の距離を測定する方法。
- 実際には、three、fiveのような少数の隣人を使用することはしばしばうまくいきますが、このパラメータを調整する必要があります。
- 正しい距離メジャーを選択するのはやや難しいです。, デフォルトでは、ユークリッド距離が使用され、多くの設定でうまく機能します。
k-NNの強みの一つは、モデルが非常に理解しやすく、多くの場合、調整の多くなしに合理的なパフォーマンスを提供することです。 このアルゴリズムが良いベースライン方法を試してみを考慮した、より高度な技術です。 最近傍モデルの構築は通常は非常に高速ですが、トレーニングセットが非常に大きい場合(特徴量の数またはサンプル数のいずれか)、予測が遅くなる可 K-NNアルゴリズムを使用する場合は、データを前処理することが重要です。, このアプローチは、多くのフィーチャ(数百以上)を持つデータセットではうまく機能せず、ほとんどのフィーチャがほとんどの場合0であるデータセット(いわゆる
結論として
k最近傍アルゴリズムは、データを分類するための簡単で効果的な方法です。 これは、機械学習アルゴリズムを実行するためにデータのインスタンスを近くに持つ必要があるインスタンスベースの学習の例です。 大規模なデータセットの場合、これは大量のストレージを意味します。, さらに、データベース内のすべてのデータの距離測定を計算する必要があり、これは面倒な場合があります。 各クラスの”平均”または”例”インスタンスがどのように見えるかはわかりません。
したがって、最も近いk-neighborsアルゴリズムは理解しやすいですが、予測が遅く、多くの機能を処理できないため、実際にはあまり使用されません。,
リファレンスソース:
- Peter Harrington(2012)による機械学習の実践
- Sarah Guido and Andreas Muller(2016)によるPythonによる機械学習の概要















