k-가장 가까운 이웃:당신과 가까운 사람은 누구입니까?
대학에 간다면 적어도 몇 명의 학생 단체에 참여했을 것입니다. 저는 Rochester Tech 에서 대학원생으로 1 학기를 시작하고 있으며 여기에는 350 개 이상의 조직이 있습니다. 그들은 학생의 관심사에 따라 다른 범주로 분류됩니다. 이러한 범주를 정의하는 것은 무엇이며 어떤 조직이 어떤 범주로 들어가는 지 누가 말합니까? 나는 확실하라고 요청했다면 사람들이 실행한 단체,그들이 말하지 않는 자신의 org 처럼 다른 사람의 조직,그러나 어떤 방법을 알고 있는 그들은 비슷합니다., 형제애와 여학생은 그리스 생활에 동일한 관심을 가지고 있습니다. 교내 축구와 클럽 테니스는 스포츠에 동일한 관심을 가지고 있습니다. 라틴계 그룹과 아시아계 미국인 그룹은 문화 다양성에 대해 동일한 관심을 가지고 있습니다. 아마도 이러한 조직에 의해 실행되는 이벤트 및 회의를 측정 한 경우 조직이 속한 범주를 자동으로 파악할 수 있습니다. 내가 사용하여 학생 단체의 일부를 설명하는 개념 k-가장 가까운 이웃,틀림없이 가장 간단한 기계 학습 알고리즘은 거기에있다. 모델 구축은 학습 데이터 세트를 저장하는 것으로 만 구성됩니다., 을 예측에 대한 새로운 데이터는 점,알고리즘을 발견한 가장 가까운 데이터 포인트에서 훈련 데이터 집합의”가장 가까운 이웃이 있습니다.”
작동 방법
에서는 가장 간단한 버전,k-NN 알고리즘만 고려 정확히 하나의 가장 가까운 이웃이 있는,가장 가까운 교육 데이터 지점을 지점에 우리가 원하는 예측하다. 그런 다음 예측은 단순히이 훈련 지점에 대해 알려진 출력입니다., 아래 그림은 이것을 설명한 케이스의 분류에서 위조 데이터 집합:

여기에, 우리가 추가되는 세 가지 새로운 데이터 포인트 다음과 같이 표시된다. 그들 각각에 대해,우리는 훈련 세트에서 가장 가까운 지점을 표시했습니다. 가장 가까운 이웃 알고리즘의 예측은 해당 지점의 레이블입니다(십자가의 색으로 표시).
가장 가까운 이웃 만 고려하는 대신 이웃의 임의의 숫자 인 k 를 고려할 수도 있습니다., 이것은 k-가장 가까운 이웃 알고리즘의 이름이 나오는 곳입니다. 둘 이상의 이웃을 고려할 때 투표를 사용하여 레이블을 할당합니다. 즉,각 테스트 포인트에 대해 클래스 0 에 속한 이웃 수와 클래스 1 에 속한 이웃 수를 계산합니다. 그런 다음 우리는 더 자주 클래스를 할당:즉,k-가장 가까운 이웃 중 대다수 클래스., 다음 예에서 사용하는 다섯 가장 가까운 이웃:
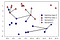
시 예측은 다음과 같의 색상으로 십자가입니다. 왼쪽 상단의 새 데이터 포인트에 대한 예측이 하나의 이웃 만 사용했을 때의 예측과 동일하지 않다는 것을 알 수 있습니다.
이 그림에는 이진 문제 분류,이 방법을 적용할 수 있는 데이터의 수와 함께 클래스입니다., 더 많은 클래스를,우리는 얼마나 많은 이웃에 속한 각 클래스고 다시 예측하는 가장 일반적인 클래스입니다.,완화하기 위해
Python 코드 기능에 대한 여기에 있습니다:
의 조금 더 깊이 파고 코드:
- 기능 knnclassify 걸리는 4 개의 입력:입력 벡터를 분류하라고,전체 매트릭스의 훈련 예라고 데이터 집합,벡터의 라벨이라는 라벨 k—의 수는 가장 가까운 이웃에서 사용하는 투표입니다., 레이블 벡터는 데이터 집합 행렬에 행이 있는 만큼 그 안에 많은 요소가 있어야 합니다.
- 우리는 유클리드 거리를 사용하여 A 와 현재 지점 사이의 거리를 계산합니다.
- 그런 다음 거리를 증가하는 순서로 정렬합니다.
- 다음에,낮은 k 거리 사용되는 투표에서 클래스 a
- 그 후에,우리는 classCount 사전하고 분해 목록으로 튜플을 정렬합 튜플여 2 번째 항목에서 튜플입니다. 정렬은 역으로 이루어 지므로 가장 큰 것부터 가장 작은 것까지 있습니다.,
- 마지막으로 가장 자주 발생하는 항목의 레이블을 반환합니다.
구현을 통해 은 배우
지금 보자에서 우리가 어떻게 구현할 수 있습 kNN 알고리즘을 사용하여 와 이를 배울:
들에 대해 자세히 살펴보도록 하자 코드:
- 첫째,우리가 생성 iris 합니다.
- 그런 다음 데이터를 교육 및 테스트 세트로 분할하여 일반화 성능을 평가합니다.
- 다음으로 이웃 수(k)를 5 로 지정합니다.
- 다음으로,우리는 훈련 세트를 사용하여 분류자를 맞 춥니 다.,
- 테스트 데이터에 대한 예측을하기 위해 예측 방법을 호출합니다. 각 데이터 관점에서 테스트를 설정하는 방법을 계산한 가장 가까운 이웃에서 훈련을 설정하고 찾아내는 가장 일반적인 클래스들이다.
- 마지막으로 테스트 데이터 및 테스트 레이블로 점수 메서드를 호출하여 모델이 얼마나 잘 일반화되는지 평가합니다.
실행하는 모델은 우리에게 시험을 설정 정확도 97%이상의 의미하는 모델을 예측 등에 대해 올바르게 97%의에서 샘플을 테스트합니다.,

강점과 약점
원칙적으로,두 개의 중요한 매개 변수를 KNeighbors 분류 수의 이웃과 어떻게 당신 사이의 거리를 측정 데이터 포인트입니다.
- ,실제 사용하여 소수의 이웃과 같은 세 가지 또는 다섯 개의 자주 잘 작동,하지만 당신은 확실히 조정이 매개 변수입니다.
- 올바른 거리 측정을 선택하는 것은 다소 까다 롭습니다., 기본적으로 유클리드 거리가 사용되어 많은 설정에서 잘 작동합니다.
k-NN 의 강점 중 하나는 모델이 매우 이해하기 쉽고 종종 많은 조정없이 합리적인 성능을 제공한다는 것입니다. 이 알고리즘을 사용하면보다 진보 된 기술을 고려하기 전에 시도 할 수있는 좋은 기준 방법입니다. 건물은 가장 가까운 이웃 사람 모형은 일반적으로 매우 빠른하지만,때의 교육을 설정은 매우 큰(중 하나에서는 기능 또는 수의 샘플)예측 속도가 느려질 수 있습니다. K-NN 알고리즘을 사용할 때 데이터를 전처리하는 것이 중요합니다., 이러한 접근 방식은 종종하지 않을 수행론에서 데이터 많은 기능을 가진(수백 또는 그 이상),그리고 그것은 특히 심하게 데이터 세트는 대부분의 기능은 0 의 대부분은 시간(그라파스는 데이터 집합).
에서 결론
k-가장 가까운 이웃 알고리즘을 간단하고 효과적인 방법으로 데이터를 분류하여. 그것은 예를 들어의 인스턴스-기반 학습,필요가 있을 경우 데이터의 손에 가까운 수행하는 기계 학습 알고리즘이 있습니다. 이 알고리즘은 전체 데이터 세트를 수행해야하며 대용량 데이터 세트의 경우 많은 양의 스토리지를 의미합니다., 또한 데이터베이스의 모든 데이터 조각에 대한 거리 측정을 계산해야하므로 번거로울 수 있습니다. 추가적인 단점은 kNN 을 제공하지 않 당신이 어떤 아이디어의 기본 구조의 데이터를 당신이 무슨 생각이 없는”average”또는”표본”인스턴스를 각 클래스에서의 모습입니다.가장 가까운 k-neighbors 알고리즘은 이해하기 쉽지만 예측이 느리고 많은 기능을 처리 할 수 없기 때문에 실제로는 자주 사용되지 않습니다.,
참고 자료:
- Peter Harrington 의 Machine Learning In Action(2012)
- Sarah Guido 와 Andreas Muller 의 Python 으로 기계 학습 소개(2016)















