Avslutande mellanslag i SQL Server
titta på veckans video på YouTube
för länge sedan byggde jag ett program som fångade användarinmatning. En funktion i programmet var att jämföra användarens inmatning mot en databas med värden.
appen utförde denna textjämförelse som en del av en SQL Server lagrad procedur, så att jag enkelt kan uppdatera affärslogiken i framtiden om det behövs.
en dag fick jag ett e-postmeddelande från en användare som sa att värdet de skrev in matchade med ett databasvärde som de visste inte skulle matcha., Det är den dagen jag upptäckte SQL Server counter intuitiv jämlikhet jämförelse när det handlar om avslutande mellanslag tecken.
Vadderat vitt utrymme
du är förmodligen medveten om att CHAR-datatypen pads värdet med mellanslag tills den definierade längden uppnås:
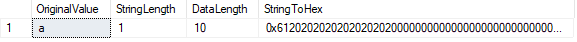
LEN () – funktionen visar antalet tecken i vår sträng, medan DATALENGTH () – funktionen visar oss antalet byte som används av den strängen.
i detta fall är DATALÄNGDEN lika med 10., Detta resultat beror på vadderade utrymmen inträffar efter tecknet ” a ” för att fylla den definierade röding Längd 10. Vi kan bekräfta detta genom att konvertera värdet till hexadecimal. Vi ser värdet 61 (”A” I hex) följt av nio” 20 ” värden (mellanslag).
om vi ändrar variabelns datatyp till VARCHAR ser vi att värdet inte längre är vadderat med mellanslag:

Med tanke på att en av dessa datatyper pads värden med mellanslagstecken medan den andra inte gör det, vad händer om vi jämför de två?,
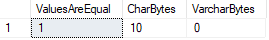
i det här fallet anser SQL Server båda värdena lika, även om vi kan bekräfta att DATALENGTHs är olika.
detta beteende uppstår inte bara med blandade datatypjämförelser. Om vi jämför två värden av samma datatyp, med ett värde som innehåller flera mellanslagstecken, upplever vi något…oväntat:

även om våra två variabler har olika värden (ett tomt jämfört med fyra mellanslagstecken) anser SQL Server att dessa värden är lika.,
om vi lägger till ett tecken med vissa avslutande blanktecken ser vi samma beteende:

båda värdena är tydligt olika, men SQL Server anser att de är lika med varandra. Att byta vårt likhetstecken till en liknande operatör ändrar saker något:

även om jag skulle tro att en liknande utan jokertecken skulle uppträda precis som ett likhetstecken, Utför SQL Server inte dessa jämförelser på samma sätt.,
om vi byter tillbaka till vår equal sign jämförelse och prefix vårt teckenvärde med mellanslag kommer vi också att märka ett annat resultat:

SQL Server anser två värden lika oavsett mellanslag som inträffar i slutet av en sträng. Mellanslag före en sträng men inte längre betraktas som en match.
vad händer?
ANSI
medan counter intuitiv är SQL Server funktionalitet motiverad., SQL Server följer ANSI-specifikationen för att jämföra strängar och lägger till vitt utrymme i strängar så att de är lika långa innan de jämförs. Detta förklarar de fenomen vi ser.
det gör inte detta med den liknande operatören, vilket förklarar skillnaden i beteende.
jämförelser när extra mellanslag spelar roll
låt oss säga att vi vill göra en jämförelse där skillnaden i avslutande mellanslag spelar roll.
ett alternativ är att använda liknande operatör som vi såg några exempel tillbaka., Det här är inte den typiska användningen av den liknande operatören, så var noga med att kommentera och förklara vad din fråga försöker göra genom att använda den. Det sista du vill ha är en framtida utvecklare av din kod för att byta tillbaka till ett lika tecken eftersom de inte ser några wild card-tecken.
ett annat alternativ som jag har sett är att utföra en DATALÄNGDSJÄMFÖRELSE utöver värdejämförelsen:

denna lösning är dock inte rätt för varje scenario., Till att börja med, du har inget sätt att veta om SQL Server kommer att köra ditt värde jämförelse eller datalength predikat först. Detta kan förstöra förödelse på indexanvändning och orsaka dålig prestanda.
ett allvarligare problem kan uppstå om du jämför fält med olika datatyper., När du till exempel jämför en varchar med nvarchar-datatyp är det ganska enkelt att skapa ett scenario där din jämförelsefråga med DATALENGTH kommer att utlösa en falsk positiv:

här lagrar NVARCHAR 2 byte för varje tecken, vilket gör att DATALENGTHs av ett enda tecken NVARCHAR är lika med ett tecken + ett utrymme varchar-värde.
det bästa du kan göra i dessa scenarier är att förstå dina data och välja en lösning som fungerar för just din situation.,
och kanske trimma dina data innan insättning (om det är vettigt att göra det)!















