K-närmaste grannar: Vem är nära dig?
om du går på college har du förmodligen deltagit i minst ett par studentorganisationer. Jag börjar min 1: A terminen som doktorand på Rochester Tech, och det finns mer än 350 organisationer här. De sorteras i olika kategorier baserat på studentens intressen. Vad definierar dessa kategorier, och vem säger vilken organisation som går in i vilken kategori? Jag är säker på att om du frågade de personer som driver dessa organisationer, skulle de inte säga att deras organisation är precis som någon annans organisation, men på något sätt vet du att de är likartade., Broderskap och kvinnoföreningar har samma intresse i det grekiska livet. Intramural fotboll och klubb tennis har samma intresse för sport. Latino-gruppen och den asiatiska amerikanska gruppen har samma intresse för kulturell mångfald. Kanske om du mätte händelserna och mötena som drivs av dessa organisationer, kan du automatiskt räkna ut vilken kategori en organisation tillhör. Jag använder studentorganisationer för att förklara några av begreppen k-närmaste grannar, utan tvekan den enklaste maskininlärningsalgoritmen där ute. Att bygga modellen består endast av att lagra träningsdatauppsättningen., För att göra en förutsägelse för en ny datapunkt hittar algoritmen närmaste datapunkter i träningsdatauppsättningen — dess ”närmaste grannar.”
hur det fungerar
i sin enklaste version anser k-nn-algoritmen bara exakt en närmaste granne, vilket är den närmaste träningsdatapunkten till den punkt vi vill göra en förutsägelse för. Förutsägelsen är då helt enkelt den kända produktionen för denna träningspunkt., Figur nedan visar detta för fallet med Klassificering på forge dataset:

Här har vi lagt till tre nya datapunkter, visas som stjärnor. För var och en av dem markerade vi närmaste punkt i träningsuppsättningen. Förutsägelsen av den närmaste grannalgoritmen är etiketten för den punkten (visas av korsets färg).
istället för att bara överväga närmaste granne kan vi också överväga ett godtyckligt nummer, k, av grannar., Det är här namnet på K-närmaste grannsalgoritmen kommer ifrån. När vi överväger mer än en granne använder vi omröstning för att tilldela en etikett. Det betyder att för varje testpunkt räknar vi hur många grannar som tillhör klass 0 och hur många grannar som tillhör klass 1. Vi tilldelar sedan klassen som är vanligare: med andra ord majoritetsklassen bland de närmaste grannarna., Följande exempel använder de fem närmaste grannarna:
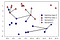
igen visas prediktionen som korsets färg. Du kan se att förutsägelsen för den nya datapunkten längst upp till vänster inte är densamma som förutsägelsen när vi bara använde en granne.
även om denna illustration är för ett binärt klassificeringsproblem, kan denna metod tillämpas på datauppsättningar med valfritt antal klasser., För fler klasser räknar vi hur många grannar som hör till varje klass och förutspår igen den vanligaste klassen.,lättar ordning
Python-koden för funktionen är här:
låt oss gräva lite djupare in i koden:
- funktionen knnclassify tar 4 ingångar: inmatningsvektorn för att klassificera kallad A, en fullständig matris av träningsexempel som heter dataset, en vektor av etiketter som heter etiketter och k-antalet närmaste grannar att använda i omröstningen., Etikettvektorn ska ha så många element i den som det finns rader i datauppsättningsmatrisen.
- vi beräknar avstånden mellan A och den aktuella punkten med hjälp av euklidiska avståndet.
- sedan sorterar vi avstånden i en ökande ordning.
- därefter används de lägsta k-avstånden för att rösta på klassen A.
- efter det tar vi classCount-ordlistan och sönderdelar den i en lista över tuples och sorterar sedan tuplesna med 2: a objektet i tuple. Sorten görs i omvänd ordning så vi har den största till minsta.,
- slutligen returnerar vi etiketten på objektet som förekommer oftast.
implementering Via Scikit-Learn
låt oss nu ta en titt på hur vi kan implementera kNN-algoritmen med scikit-learn:
låt oss titta in i koden:
- först genererar vi koden: Iris dataset.
- sedan delar vi våra data i en träning och testuppsättning för att utvärdera generaliseringsprestanda.
- därefter anger vi antalet grannar (k) till 5.
- därefter passar vi klassificeraren med träningsuppsättningen.,
- för att göra förutsägelser om testdata kallar vi predict-metoden. För varje datapunkt i testuppsättningen beräknar metoden sina närmaste grannar i träningsuppsättningen och finner den vanligaste klassen bland dem.
- slutligen utvärderar vi hur bra vår modell generaliserar genom att ringa poängmetoden med testdata och testetiketter.
kör modellen bör ger oss en testuppsättning noggrannhet på 97%, vilket innebär att modellen förutspådde klassen korrekt för 97% av proverna i testdatauppsättningen.,

styrkor och svagheter
i princip finns det är två viktiga parametrar till kneighbors klassificerare: antalet grannar och hur du mäter avståndet mellan datapunkter.
- i praktiken fungerar ett litet antal grannar som tre eller fem ofta bra, men du bör säkert justera denna parameter.
- att välja rätt avståndsmått är något knepigt., Som standard används euklidiskt avstånd, vilket fungerar bra i många inställningar.
en av styrkorna i k-NN är att modellen är mycket lätt att förstå, och ger ofta rimlig prestanda utan många justeringar. Att använda denna algoritm är en bra baslinje metod att försöka innan man överväger mer avancerade tekniker. Att bygga närmaste grannmodell är vanligtvis mycket snabb, men när din träningsuppsättning är mycket stor (antingen i antal funktioner eller i antal prover) förutsägelse kan vara långsam. När du använder k-nn-algoritmen är det viktigt att förbehandla dina data., Detta tillvägagångssätt fungerar ofta inte bra på datauppsättningar med många funktioner (hundratals eller fler), och det gör särskilt dåligt med datauppsättningar där de flesta funktioner är 0 för det mesta (så kallade glesa datauppsättningar).
Sammanfattningsvis
k-närmaste Grannalgoritmen är ett enkelt och effektivt sätt att klassificera data. Det är ett exempel på instansbaserat lärande, där du måste ha instanser av data nära till hands för att utföra maskininlärningsalgoritmen. Algoritmen måste bära runt hela datauppsättningen; för stora datauppsättningar innebär detta en stor mängd lagring., Dessutom måste du beräkna avståndsmätning för varje del av data i databasen, och detta kan vara besvärligt. En ytterligare nackdel är att kNN inte ger dig någon aning om den underliggande strukturen av data; du har ingen aning om vad en ”genomsnittlig” eller ”exempel” instans från varje klass ser ut.
så, medan närmaste K-neighbors algoritm är lätt att förstå, används den inte ofta i praktiken, på grund av att förutsägelsen är långsam och oförmågan att hantera många funktioner.,
referenskällor:
- maskininlärning i aktion av Peter Harrington (2012)
- introduktion till maskininlärning med Python av Sarah Guido och Andreas Muller (2016)















