Etterfølgende Mellomrom i SQL Server
Se denne ukens video på YouTube
for lenge siden jeg bygget et program som fanget brukerundersøkelser. En funksjon av programmet var å sammenligne brukerens input mot en database av verdier.
appen utført denne teksten sammenligningen som en del av en SQL Server lagret prosedyre, tillater meg å oppdatere forretningslogikken i fremtiden dersom det er nødvendig.
En dag, fikk jeg en e-post fra en bruker å si at den verdi de ble skrevet i var samsvarende med en database verdi som de visste ikke bør matche., Det er den dagen jeg oppdaget SQL Server counter intuitive likestilling sammenligningen når du arbeider med etterfølgende mellomrom.
Polstret mellomrom
Du er sannsynligvis klar over at RØYE data type pads verdien med plass til definert lengde er nådd:
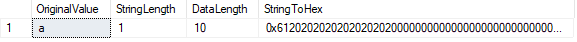
LEN () – funksjonen viser antall tegn i vår string, mens DATALENGTH () – funksjonen, som viser antall byte som brukes av at strengen.
I dette tilfellet, DATALENGTH er lik 10., Dette resultatet skyldes polstret områder som er oppstått etter at karakteren «a» for å fylle definert CHAR lengde på 10. Vi kan bekrefte dette ved å konvertere verdi til ascii. Vi ser verdien 61 («a» i hex) etterfulgt av ni «20» verdier (mellomrom).
Hvis vi endrer vår variabel data type VARCHAR, vi vil se verdien er ikke lenger polstret med mellomrom:

Gitt at en av disse datatypene pads verdier med mellomrom mens den andre ikke gjør det, hva skjer hvis vi sammenligner de to?,
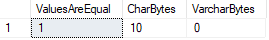
I dette tilfellet SQL Server omfatter både verdier som er lik, selv om vi kan bekrefte at DATALENGTHs er forskjellige.
Denne atferden ikke forekommer kun med blandet data type sammenligninger imidlertid. Hvis vi sammenligne to verdier av samme datatype, med en verdi som inneholder flere mellomrom, vi opplever noe…uventet:

Selv om våre to variablene har ulike verdier (en blank forhold til fire mellomrom), SQL Server betrakter disse verdiene like.,
Hvis vi legge til en karakter med noen etterfølgende mellomrom vil vi se det samme problemet:

Begge verdiene er klart forskjellige, men SQL Server anser dem for å være lik hverandre. Bytte vår lik-tegnet til en SOM operatør endringer ting litt:

Selv om jeg vil tro at en SOM uten noen jokertegn ville oppføre seg akkurat som et likhetstegn, SQL Server ikke utføre disse sammenligningene samme måte.,
Hvis vi gå tilbake til vår lik-tegnet sammenligningen og prefiks vår karakter verdi med mellomrom vil vi også legge merke til et annet resultat:

SQL Server vurderer to verdier som er lik uavhengig av plasser skjer på slutten av en streng. Mellomrom før en streng imidlertid ikke lenger ansett som en kamp.
Hva er det som skjer?
ANSI
Mens counter intuitive, SQL Server funksjonalitet er berettiget., SQL Server følger ANSI-spesifikasjon for sammenligning av strenger, legge til mellomrom for å strenger, slik at de har samme lengde før sammenligne dem. Dette forklarer fenomener vi ser.
Det gjør ikke dette med SOM operatør imidlertid, som forklarer forskjellen i atferd.
Sammenligninger når ekstra mellomrom saken
La oss si at vi ønsker å gjøre en sammenligning hvor forskjellen i etterfølgende mellomrom saker.
Ett alternativ er å bruke den SOM operatør, som vi så et par eksempler tilbake., Dette er ikke den typiske bruken av den SOM operatør imidlertid, så vær sikker på å kommentere og forklare hva din henvendelse forsøker å gjøre ved å bruke det. Det siste du ønsker er noen fremtid utvikleren av kode for å slå den tilbake til et likhetstegn fordi de ikke ser noen jokertegn.
et Annet alternativ som jeg har sett på, er å utføre en DATALENGTH sammenligningen i tillegg til verdien sammenligning:

Denne løsningen er ikke riktig for alle tenkelige imidlertid., For det første, du har ingen måte å vite hvis SQL Server vil utføre verdi sammenligning eller DATALENGTH predikat første. Dette kan vraket ødeleggelse på indeksen bruk og føre til dårlig ytelse.
Et mer alvorlig problem kan oppstå hvis du sammenligner felt med ulike datatyper., For eksempel, når man sammenligner en VARCHAR å NVARCHAR datatype, det er ganske enkelt å lage et scenario der sammenligningen spørring ved hjelp av DATALENGTH vil utløse en falsk positiv:

Her NVARCHAR butikkene 2 byte for hvert tegn, forårsaker DATALENGTHs av et enkelt tegn, NVARCHAR å være lik et tegn + en plass VARCHAR verdi.
Den beste tingen å gjøre i disse scenariene er å forstå dataene dine og plukke en løsning som vil fungere for din spesielle situasjon.,
Og kanskje trimme dine data før innsetting (hvis det er fornuftig å gjøre det)!















