k-Nærmeste Naboer: Hvem er nær deg?
Hvis du går til college, har du sannsynligvis har deltatt i minst et par av studentorganisasjonene. Jeg begynner min 1. semester som en graduate student ved Rochester Tech, og det er mer enn 350 organisasjoner her. De er sortert i ulike kategorier basert på studentenes egne interesser. Hva som definerer disse kategoriene, og som sier noe org går inn på hvilken kategori du? Jeg er sikker på at hvis du spør folk som kjører disse organisasjonene, de ville ikke si at deres org er akkurat som noen andre org, men på en eller annen måte du vet at de er like., Fraternities og sororities har samme interesse i gresk Liv. Egenutført fotball og tennis club har samme interesse i sport. Latino-gruppen og Asiatisk-Amerikanske konsernet har samme interesse i kulturelt mangfold. Kanskje hvis du målte arrangementer og møter som drives av disse orgs, du kan automatisk finne ut hvilken kategori en organisasjon tilhører. Jeg vil bruke studentenes organisasjoner til å forklare noen av begrepene k-Nærmeste Naboer, uten tvil den enkleste maskinlæring algoritmen ut det. Bygningen modellen består bare av lagring trening dataset., For å gjøre en prediksjon for en ny datapunkt, algoritmen finner den nærmeste data poeng i trening dataset — sin «nærmeste naboer.»
Hvordan Det Fungerer
I sin enkleste versjon, k-NN-algoritmen vurderer bare nøyaktig ett nærmeste nabo, som er den nærmeste treningsdata punkt til det punktet vi ønsker å lage en prediksjon for. Prediksjon er da ganske enkelt kjent utgang for denne opplæringen punkt., Figuren nedenfor illustrerer dette for tilfelle av klassifisering på smia dataset:

Her vi har lagt til tre nye data poeng, som vises som stjerner. For hver av dem, vi merket det nærmeste punktet i trening sett. Prediksjon av ett-nærmeste-nabo algoritmen er etiketten for at punkt (vist med farge på korset).
Stedet for å vurdere bare de nærmeste nabo, vi kan også vurdere et vilkårlig antall, k, av naboer., Dette er navnet på k-nærmeste naboer algoritme kommer fra. Når du vurderer mer enn én nabo, vi bruker å stemme for å tilordne en etikett. Dette betyr at for hver test punktet, vi telle hvor mange naboer hører til i klasse 0 og hvor mange naboer hører til i klasse 1. Vi vil deretter tildele den klassen som er mer hyppig: med andre ord, de fleste klasse blant k-nærmeste naboer., Følgende eksempel bruker de fem nærmeste naboer:
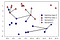
Igjen, forslaget er vist som fargen på korset. Du kan se at forslaget om nye data punkt på øverst til venstre er ikke det samme som prediksjon når vi brukte kun én nabo.
Mens denne illustrasjonen er for en binær klassifisering problem, denne metoden kan brukes til å datasett med en rekke klasser., For flere klasser, vi teller hvor mange naboer hører til hver enkelt klasse og igjen forutsi den mest vanlige klassen.,lettelser for
Python-koden for funksjonen er her:
La oss grave litt dypere inn koden:
- funksjonen knnclassify tar 4 innganger: inngang vektor å klassifisere som kalles En, en full matrise av trening eksempler kalt dataSet, en vektor av etiketter kalt etiketter, og k — antall nærmeste naboer til bruk i avstemningen., Etikettene vektor bør ha så mange elementer i det som det er rader i datasettet matrise.
- Vi beregne avstander mellom En og gjeldende tilgangspunktet ved hjelp av Euclidean distance.
- Så vi sortere avstander i en stigende rekkefølge.
- Neste, den laveste k avstander er brukt til å stemme på klasse A.
- Etter det, tar vi classCount ordbok og brytes ned det inn en liste av tupler, og deretter sortere tupler av 2. element i tuple. Sorteringen gjøres i omvendt, slik at vi har den største til minste.,
- til Slutt, vi kommer tilbake til etiketten på element som forekommer oftest.
Implementering Via Scikit-Lær
la oss Nå ta en titt på hvordan vi kan implementere kNN algoritme ved hjelp av scikit-lære:
La oss se inn koden:
- Første, vi generere iris dataset.
- Så, har vi delt våre data inn i en trening og test satt til å evaluere generalisering ytelse.
- Neste, vi angi antall naboer (k) til 5.
- Neste, vi passe classifier ved hjelp av trening sett.,
- for Å gjøre forutsigelser om test data, som vi kaller forutsi metode. For hvert datapunkt i testsettet, metoden regner ut sine nærmeste naboer i trening sett og finner de mest vanlige klasse blant dem.
- til Slutt, vi evaluere hvor godt vår modell generaliserer ved å ringe score metode med test data og test etiketter.
å Kjøre modellen bør gir oss en test angi nøyaktighet på 97%, som betyr at den modellen som gjettet riktig klasse for 97% av prøvene i testen dataset.,

Styrker og Svakheter
I prinsippet er det to viktige parametere til KNeighbors classifier: antall naboer og hvordan du måle avstanden mellom datapunkter.
- I praksis, ved hjelp av et lite antall naboer som tre eller fem ofte fungerer bra, men du bør absolutt justere denne parameteren.
- for å Velge riktig avstand tiltaket er noe vanskelig., Som standard, Euclidean distance er brukt, som fungerer godt i mange innstillinger.
En av styrkene til k-NN er at modellen er veldig enkel å forstå, og ofte gir rimelige resultater uten en masse justeringer. Ved hjelp av denne algoritmen er en god baseline metode til å prøve før du vurderer mer avanserte teknikker. Bygningen nærmeste naboer modellen er vanligvis veldig fort, men når treningen sett er svært store (enten i antall funksjoner, eller i antall prøver) prediksjon kan være treg. Når du bruker k-NN algoritme, er det viktig å preprocess dine data., Denne tilnærmingen ofte ikke fungerer godt på datasett med mange funksjoner (hundrevis eller mer), og det gjør det spesielt dårlig med datasett der de fleste funksjoner er 0 mesteparten av tiden (såkalte sparsom datasett).
I Konklusjonen
k-Nærmeste Naboer algoritme er en enkel og effektiv måte å klassifisere data. Det er et eksempel på eksempel-basert læring, hvor du trenger å ha forekomster av data for hånden å utføre det maskinlæring algoritme. Algoritmen har å bære rundt på hele datasettet, for store datasett, dette innebærer en stor mengde lagringsplass., I tillegg må du beregne avstand måling for hver bit av data i databasen, og dette kan være tungvint. En ekstra ulempen er at kNN ikke gi deg noen idé om den underliggende strukturen i dataene, du har ingen anelse om hva en «gjennomsnittlig» eller «forbilde» eksempel fra hver klasse ser ut som.
Så, mens den nærmeste k-naboer algoritmen er lett å forstå, det er ikke ofte brukt i praksis, på grunn av prediksjon blir treg og sin manglende evne til å håndtere mange funksjoner.,
Referanse Kilder:
- Machine Learning In Action av Peter Harrington (2012)
- Introduksjon til maskinlæring med Python-av Sarah Guido og Andreas Müller (2016)















