k-cei mai apropiați vecini: cine sunt aproape de tine?
dacă mergeți la facultate, probabil că ați participat la cel puțin câteva organizații studențești. Încep semestrul 1st ca student absolvent la Rochester Tech și există mai mult de 350 de organizații aici. Acestea sunt sortate în diferite categorii în funcție de interesele elevului. Ce definește aceste categorii și cine spune care org intră în ce categorie? Sunt sigur că dacă ați întrebat oamenii care conduc aceste organizații, ei nu ar spune că org lor este la fel ca org altcuiva, dar într-un fel știi că sunt similare., Fraternități și sororities au același interes în viața greacă. Fotbalul Intramural și tenisul de club au același interes pentru sport. Grupul Latino și grupul Asiatic American AU același interes pentru diversitatea culturală. Poate că dacă ați măsurat evenimentele și întâlnirile conduse de aceste orgi, ați putea să vă dați seama automat din ce categorie aparține o organizație. Voi folosi organizațiile studențești pentru a explica unele dintre conceptele celor mai apropiați vecini k, probabil cel mai simplu algoritm de învățare a mașinilor de acolo. Construirea modelului constă doar în stocarea setului de date de instruire., Pentru a face o predicție pentru un nou punct de date, algoritmul găsește cele mai apropiate puncte de date din setul de date de instruire — „cei mai apropiați vecini.”
cum funcționează
în cea mai simplă versiune, algoritmul k-NN consideră exact un vecin cel mai apropiat, care este cel mai apropiat punct de date de antrenament până la punctul pentru care vrem să facem o predicție. Predicția este apoi pur și simplu ieșirea cunoscută pentru acest punct de antrenament., Figura de mai jos ilustrează acest lucru pentru cazul de clasificare pe forge set de date:

Aici, am adăugat trei noi puncte de date, prezentate ca stelele. Pentru fiecare dintre ele, am marcat cel mai apropiat punct din setul de antrenament. Predicția algoritmului celui mai apropiat vecin este eticheta acelui punct (arătată prin culoarea Crucii).în loc să luăm în considerare doar cel mai apropiat vecin, putem lua în considerare și un număr arbitrar, k, de vecini., De aici provine numele algoritmului k-cel mai apropiat vecin. Când luăm în considerare mai mulți vecini, folosim votul pentru a atribui o etichetă. Aceasta înseamnă că, pentru fiecare punct de testare, numărăm câți vecini aparțin clasei 0 și câți vecini aparțin clasei 1. Apoi atribuim clasa care este mai frecventă: cu alte cuvinte, clasa majoritară printre vecinii k-cei mai apropiați., Următorul exemplu utilizează cinci cei mai apropiați vecini:
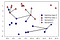
din Nou, predicția este prezentat ca culoarea de pe cruce. Puteți vedea că predicția pentru noul punct de date din stânga sus nu este aceeași cu predicția atunci când am folosit un singur vecin.
deși această ilustrație este pentru o problemă de clasificare binară, această metodă poate fi aplicată seturilor de date cu orice număr de clase., Pentru mai multe clase, numărăm câți vecini aparțin fiecărei clase și prezicem din nou cea mai comună clasă.,relaxarea scopul
cod Python pentru funcția este aici:
Să săpăm un pic mai adânc în codul:
- funcția knnclassify are 4 intrari: intrare vector pentru a clasifica numit-O, o matrice plină de exemple de instruire numit set de date, un vector de etichete numite etichete, și k — numărul de cel mai apropiat vecini pentru a utiliza la vot., Vectorul etichetelor ar trebui să aibă cât mai multe elemente în el, deoarece există rânduri în matricea setului de date.
- calculăm distanțele dintre A și punctul curent folosind distanța euclidiană.
- apoi sortăm distanțele într-o ordine crescătoare.
- Apoi, cel mai mic k distanțele sunt utilizate pentru a vota pe clasa de A.
- După aceea, vom lua classCount dicționar și se descompun într-o listă de tupluri și apoi un fel de tupluri de al 2-lea element din tuplu. Sortarea se face în sens invers, astfel încât să avem cel mai mare la cel mai mic.,
- în cele din urmă, returnăm eticheta articolului care apare cel mai frecvent.
punerea în Aplicare Prin intermediul Scikit-să Învețe
Acum, haideți să aruncăm o privire la modul în care putem implementa algoritmul kNN folosind scikit-aflați mai multe:
Să ne uităm în cod:
- în Primul rând, vom genera setul de date iris.
- apoi, ne împărțim datele într-un set de instruire și testare pentru a evalua performanța generalizării.
- apoi, specificăm numărul de vecini (k) la 5.
- apoi, încadrăm clasificatorul folosind setul de instruire.,
- pentru a face predicții cu privire la datele de testare, numim metoda de predicție. Pentru fiecare punct de date din setul de testare, metoda calculează cei mai apropiați vecini din setul de instruire și găsește cea mai comună clasă dintre ei.
- în cele din urmă, evaluăm cât de bine generalizează modelul nostru apelând metoda score cu date de testare și etichete de testare.
rularea modelului ar trebui să ne ofere o precizie a setului de testare de 97%, ceea ce înseamnă că modelul a prezis corect clasa pentru 97% din eșantioanele din setul de date al testului.,

punctele Forte și punctele Slabe
În principiu, există doi parametri importanți pentru KNeighbors clasificator: numărul de vecini și cum vă măsurați distanța dintre punctele de date.în practică, utilizarea unui număr mic de vecini, cum ar fi trei sau cinci, funcționează adesea bine, dar cu siguranță ar trebui să ajustați acest parametru.
în concluzie
algoritmul K-cei mai apropiați vecini este o modalitate simplă și eficientă de clasificare a datelor. Este un exemplu de învățare bazată pe instanțe, unde trebuie să aveți instanțe de date la îndemână pentru a efectua algoritmul de învățare automată. Algoritmul trebuie să transporte întregul set de date; pentru seturile mari de date, aceasta implică o cantitate mare de stocare., În plus, trebuie să calculați măsurarea distanței pentru fiecare bucată de date din Baza de date, iar acest lucru poate fi greoi. Un dezavantaj suplimentar este că kNN nu vă oferă nicio idee despre structura de bază a datelor; nu aveți idee cum arată o instanță „medie” sau „exemplar” din fiecare clasă.deci, în timp ce cel mai apropiat algoritm k-neighbors este ușor de înțeles, nu este adesea folosit în practică, datorită faptului că predicția este lentă și incapacitatea sa de a gestiona multe caracteristici.,
surse de referință:
- învățarea automată în acțiune de Peter Harrington (2012)
- Introducere în învățarea automată cu Python de Sarah Guido și Andreas Muller (2016)















